The Rise of AI Image Generation: Trends and Applications You Should Know
Discover how generative AI is transforming image creation, with insights into key methodologies, emerging trends, and real-world applications.
5/5/2025
The Rise of AI Image Generation
artificial intelligence
13 min read

Today, AI is showing excellent results, especially for text-based content generation. It's able to perform all the things we need from text-based content generation, summarization, analysis, structuring, editing, to translating it to the particular language. Therefore, the need for AI image generation is becoming critical for industries to keep up with the rising demands of the competitive market.
Here, the introduction of AI image generation can reduce the time of labor from hours to minutes. Creating images from a simple prompt or guideline provides a smart way to cover your daily needs for visual elements, eventually streamlining the workflow and uplifting daily productivity.
With our article, we will help you dive deep into the world of AI image generation and make you understand the core methodologies that are fueling it, some applications and limitations involved with it, and finally, discuss the future of AI image generation.
What is AI Image Generation?
AI image generation is the process of generating images by utilizing advanced machine learning algorithms like Generative Adversarial Networks and diffusion models. For providing AI-generated images, these models function by analyzing and understanding complex underlying patterns within the provided training dataset, and eventually learns to provide realistic or stylized visuals from inputs like text prompts, semantic maps, or noise vectors.
By combining natural language processing methodologies with computer vision techniques, it essentially provides AI-generated images for artwork, concept designs, and visual assets for different industries, such as entertainment, marketing, fashion, and gaming.
Why is the need for AI Image Generation rising?
The need for AI image generation is rising as industries have to cover the demands of the evolving market trends. As with AI-powered image generation tools, industries can get fast, cost-effective, and scalable visual content. With tools like this, industries can reduce the need for redundant manual efforts of creating an image from scratch, as they can get it generated within minutes by providing simple prompts.
Through these AI image generation tools, industries as well as individuals can have creative freedom to produce customized digital content while remaining consistent with the brand tone, guidelines, and standards. The potential of generative AI models is better explained in the words of Andrej Karpathy(former Director of AI at Tesla):
"Generative models are the most exciting frontier in AI. They don't just analyze the world — they create new worlds."
While this quote highlights the essential positioning of generative AI models, it also reflects that in the future, they will not be functioning as a methodology for performing analysis only, but also providing useful, refined content.
Methodologies for AI Image Generation
To empower a large range of industrial applications, we have different models that provide their specific capabilities for the AI image generation ecosystem. For your understanding, we have enlisted some of the prominent methodologies for AI image generation:
Generative Adversarial Networks (GANs)
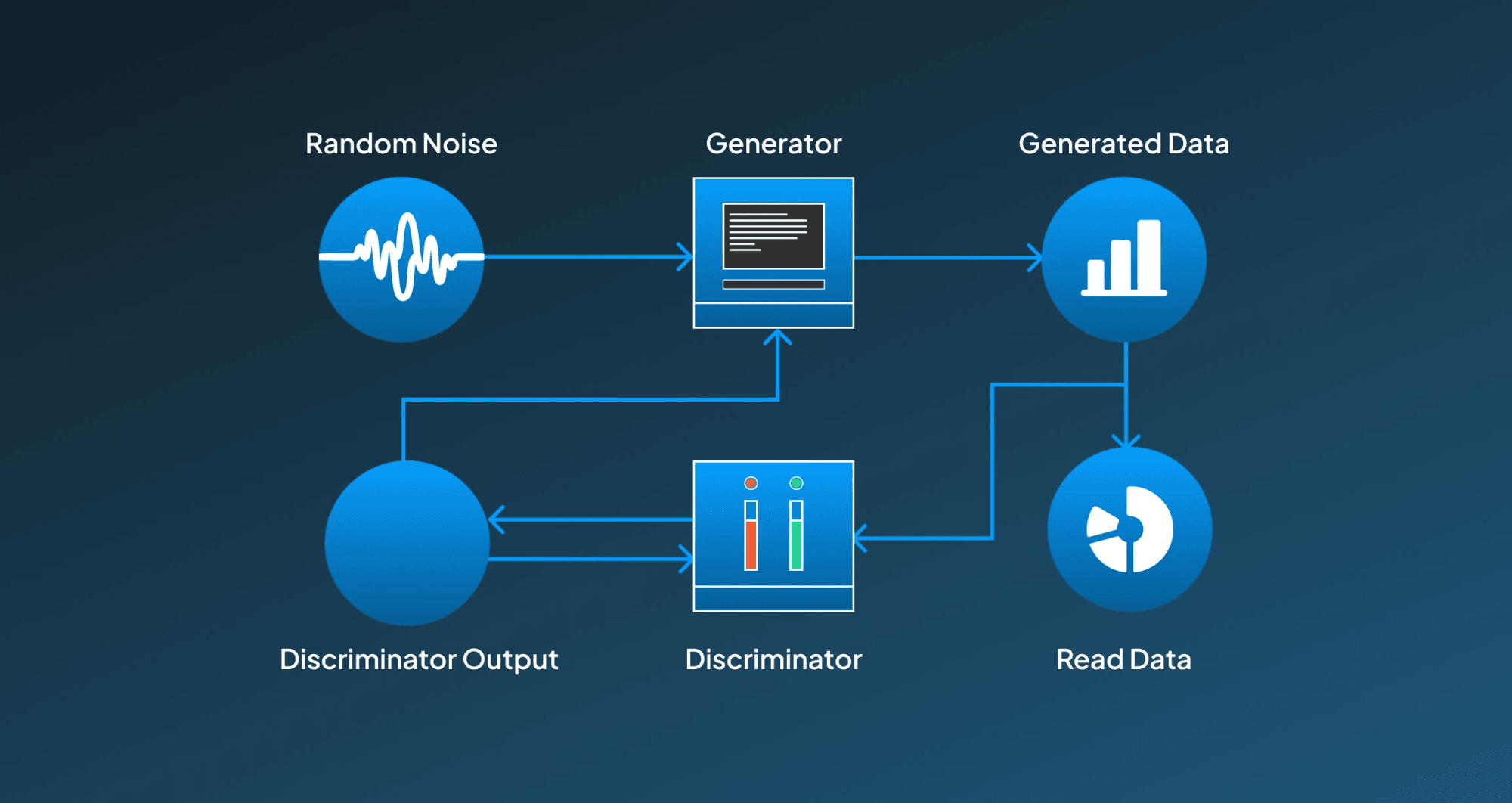
Generative Adversarial Networks, or GANs, are one of the most essential methodologies in AI image generation. It works with a combination of two competing neural networks, the generator and discriminator. Here, the generator is responsible for generating realistic images by learning from the training data. In contrast, the discriminator networks work to evaluate whether the generated image by the generator is real or fake. This adversarial network encourages the generator to improve its performance until it can produce images which is indistinguishable from the real ones for the discriminator to differentiate from the real ones.
The GANs exhibit exceptional performance in generating high-resolution, realistic images. However, they can get unstable during training and might struggle with mode collapse, in which the generator starts generating limited variations for images.
Use case:
Despite this limitation, GANs are still very commonly used for AI image generation tasks, especially for use cases like deepfakes, face generation, and artistic style transfer.
Example: StyleGAN by NVIDIA
StyleGAN is an advanced AI image generation model. It generates highly realistic images by differentiating the style elements like shape and texture. It integrates a mapping network and adaptive normalization (AdaIN) to ensure enhanced detailings at different levels, which provides precise layer manipulation to generate realistic images.
Diffusion Models
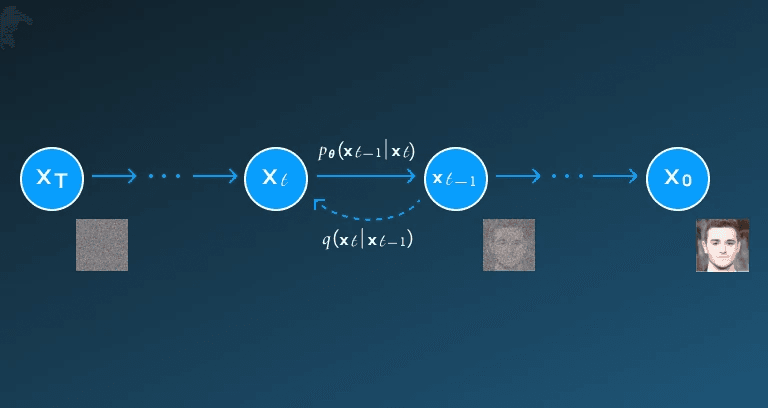
The diffusion model is a significant methodology in AI image generation, known for its ability to produce high-quality, detailed visuals. Technically, diffusion models work by simulating a two-phase process. First, during training, they perform a forward diffusion process, where clean images are gradually corrupted with noise over many time steps, typically following a Markov process. The model is then trained to learn the reverse diffusion, a denoising process that reconstructs the original image from this noisy data.
During inference, image generation begins from pure noise and proceeds iteratively through the learned reverse process to produce a realistic image. This structured approach allows for fine-grained control over image details. However, diffusion models tend to be slower than GANs due to their multi-step generation process, though they offer superior stability and semantic alignment in outputs.
Use case:
Diffusion models are commonly used for AI image generation tasks that involve text-to-image generation or image in painting, since they have more stable and precise control over the visual content they are generating.
Example: DALL-E 2 by OpenAI
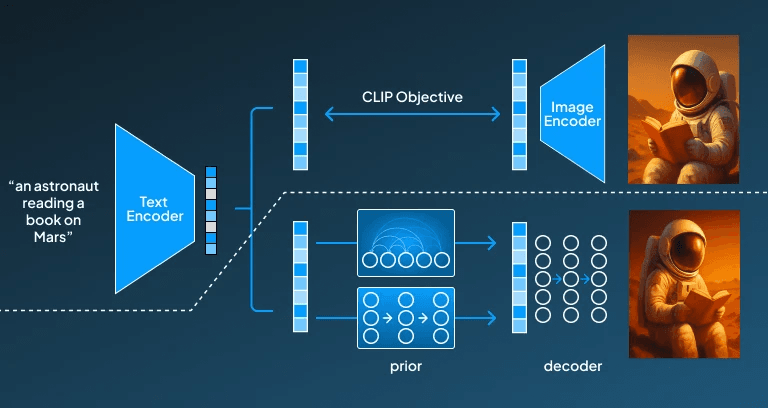
DALL-E 2 incorporates diffusion models to generate images. It begins the process of image generation with a random, noisy image, which slowly refines into a visual with particular details by going through the process of denoising. It's further guided by the integrated CLIP model that aligns the image with the given text prompt, allowing it to generate semantically accurate images.
Transformer-Based Models
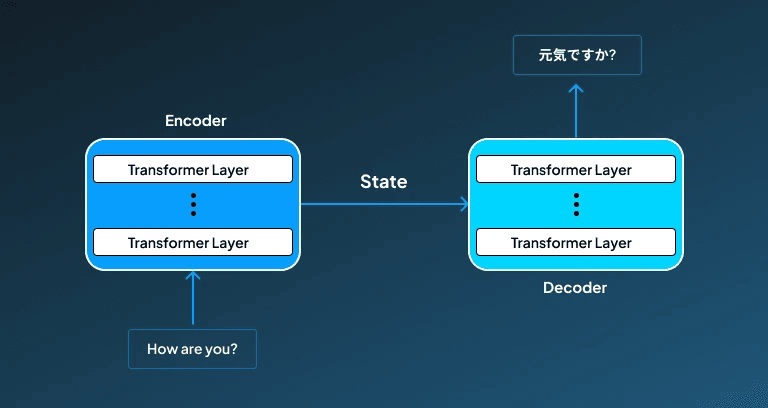
The transformer models are also being utilised for AI image generation, though they are more commonly used for natural language processing tasks. However, by taking inspiration from language processing tasks, these transformer models can also be used for AI image generation tasks. For performing image generation, it treats both texts and image generation as a sequence of tokens.
It utilizes an attention mechanism to learn deep semantic relationships between the text and visual features. They generate the required images by understanding the text-based prompts and aligning them with the visual content. However, these models require to be trained on large datasets, and demand major computing resources, which are the elements that might restrict their speed and overall performance.
Use case:
The transformer model can play an essential role in image generation applications where semantic alignment between the text and image is required, as it holds a specialized ability to generate such visuals.
Example: Imagen by Google
Imagen by Google utilizes large transformer-based language models to translate the text prompts into high-quality visual representations. This works by mapping the text prompt into a detailed embedding space, which further guides the diffusion model to generate images, with its combination enriches the semantic understanding, ultimately improving the visual results.
Variational Autoencoders (VAEs)
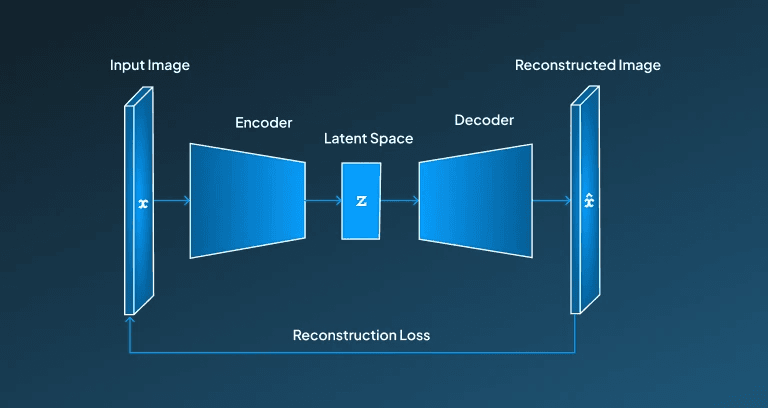
A Variational Autoencoder model can be used for AI image generation. Since it offers a more structured and easily interpretable way to generate images. It encodes the inputs and represents them in a latent space, and then further decodes them back. However, these VAEs are probabilistic models that allow them to generate multiple variations by using the same latent space, which makes them different from GANs and diffusion models.
Although the visuals produced by VAEs might not be as sharp as other models, they are computationally very efficient and convenient to train, which makes them a good approach for the AI image generation task where computational resources are limited.
Use Cases:
VAEs can be used for tasks that require interpolation, morphing, data compression, image reconstruction, or style transfer. By integrating these with other architectures, we can introduce more realism and control within the generated image content.
Example: VQ-VAE
VQ-VAE (Vector Quantized Variational Autoencoder) works by compressing images into discrete codebook tokens and further creating a compact latent space. The Diffusion models then function lower-dimensional space, to make generation efficient. This results in more resource-friendly image generation.
CLIP-Guided Generation
CLIP (Contrastive Language–Image Pre-training) is a model introduced by OpenAI, which is not essentially a generative model on its own but plays a key role in guiding image generation pipelines. CLIP operates by learning to combine representations of text and images, enabling it to evaluate how well a generated image matches the provided prompt.
While CLIP is a powerful multimodal embedding model developed to bridge text and image understanding by mapping them into a shared latent space. But it isn't a generative model itself, CLIP plays a crucial role in guiding image generation models like VQGAN and diffusion models by evaluating how well the generated images align with the input prompts. This enables more semantically accurate and contextually relevant visuals. However, its performance may weaken with abstract or highly interpretive prompts, sometimes leading to less coherent outputs.
Use Case:
The CLIP model has a great ability to enable highly accurate prompt-based image generation. So, this can specifically be used for use cases like prompt engineering or refining diffusion output.
Example: DALL·E by OpenAI
DALL-E by OpenAI implements the CLIP model to evaluate and guide image generation, making sure that the generated output aligns well with input text. Scoring the generated images based on their closeness to the provided prompt refines the quality of the final output image.
Applications of AI Image Generation in Industries
The AI image generation holds immense potential in revolutionizing industry processes. Some key areas where application of AI image generation can prove to enhance the workflow and overall performance are listed below:
AI-Powered Imagination-to-Image Converter
The AI-powered imagination to image converter is a very futuristic application that can revolutionize the entire process of creativity by bridging the gap between ideation and creation. Combining brain-computer interface (BCI) technologies like EEG or fMRI with advanced AI image generation models can decode the neural signal into visual outputs. The AI model in this reconstructs the signals into a visual expression, making the workflow convenient for artists, designers, and storytellers.
AI-Generated Dream Visualization
AI can essentially understand and visualize elements from particular dreams by combining neural data collection (via EEG or deep-learning-enhanced sleep trackers) and text-to-image diffusion models. With time, the system learns the recurring patterns that help in recalling dreams and even dream-based storytelling. With the advanced application of AI image generation of this nature, it can help the therapist in analyzing subconscious patterns, and help creators in turning it into some structured content.
Historical Scene Reconstruction
By using short text descriptions, archaeological data, or old scripts for AI model training, these models can generate a detailed reconstruction of ancient times. Through the implementation of a diffusion or transformer-based model, industries can get a realistic image of historical aspects. Such AI-generated content can be very helpful for education, museum experiences, and cultural preservation, which makes historical events accessible in a creative way for everyone.
Custom Synthetic Data for Bias-Free AI Training
The images of humans, objects, and scenes across diverse ethnicities, ages, and environments generated by these generative AI models can be used as a fuel for training AI models. This helps in encouraging bias-free training of AI models while eliminating the real-world data privacy issue. Such synthetic data can be a dataset for training models for industry applications like healthcare, security, and tech, which will directly impact ethical deployment and public trust.
Limitations in the Way of AI Image Generation
AI-driven image generation models do face some limitations, which ultimately affect the quality of image generation. Below, we have mentioned some of the limitations of AI image generation:
Bias and Ethical Concerns: One of the major limitations these image generation models face is around contain biased training data, which reinforces stereotypes. Also, deciding the boundaries of AI to reduce the high risk of misuse of these AI-generated images, especially for malicious purposes like creating deepfakes,s is a huge challenge.
Contextual and Conceptual Understanding: AI models still struggle to acquire the deeper context, ideas, and provide logical consistency in the visuals they generate, which might lead to generating a visually pleasing image that could be nonsensical or inaccurate, depending on the requirement.
Creativity and Originality Limitations: AI models still struggle with creating content that has creativity and originality, since they try to mimic the pattern they learned from the training dataset, rather than creating original art that depicts a new creative perspective.
Legal and Copyright Challenges: The question around ownership of these AI-generated images, and use of copyrighted training data is an aspect that still needs to be decided, by framing some legal standards and policies.
Technical and Computational Constraints: For generating high-quality images with visual detailing, these models require significantly high computational resources, which is another great challenge in the way of AI image generation.
User Control and Accessibility: In order to get the most suitable output, users might need to know a complex prompt or have technical skills, which limits the accessibility of these AI image generation tools.
Quality Issues and Visual Artifacts: The image generated by these AI models might not provide the best quality outputs, and it could contain unrealistic details, such as distorted faces, hands, or text, which don't fulfill the user's requirement.
Future of AI Image Generation
The future of AI image generation holds immense potential, win advancements pushing the boundaries of AI models, particularly for AI image generation, which reflects creativity, realism, and efficiency. As these AI generative models evolve, we can expect AI to create more detailed, hyper-realistic images that are indistinguishable from human-made visuals.
With the integration of advanced AI technologies, we can anticipate AI enabling personalized dream visualization, real-time emotional art rendering, AI-powered film storyboarding, and neuro-responsive fashion design, completely transforming the world we have now.
While AI continues its efforts to introduce convenience and quality with its generated artistic pieces, the major concern in the future will be around the ethical boundaries and data privacy of these AI-generated images, which need to be addressed wisely in order to ensure safe and ethical technology innovation.
Conclusion
AI image generation is rapidly revolutionizing various industries by offering faster, more efficient, and cost-effective methods for creating visual content. By utlizing foundational methodologies like GANs, diffusion models, and transformers to innovative applications such as AI-powered imagination converters and dream visualization, the technology is making the impossible possible today.
Its ability from conceptualizing to generating tailored images based on provided input prompts is indeed transformative for all the spaces. As these innovations are discovering new possibilities for industries like entertainment, it is really important to address the ethical and legal concerns to ensure safe advancements.
Are you ready to implement an AI image generation tool to optimize your workflow? Share your ideas with our experts at Centrox AI, and bring your ideas to life.

Muhammad Haris Bin Naeem
Muhammad Harris Bin Naeem, CEO and Co-Founder of Centrox AI, is a visionary in AI and ML. With over 30+ scalable solutions he combines technical expertise and user-centric design to deliver impactful, innovative AI-driven advancements.
Do you have an AI idea? Let's Discover the Possibilities Together. From Idea to Innovation; Bring Your AI solution to Life with Us!
Your AI Dream, Our Mission
Partner with Us to Bridge the Gap Between Innovation and Reality.