Deepseek-V3.1 vs GPT-4.1: Understanding the Key Differences in Large Language Models
Comparing Deepseek-V3.1 and GPT-4.1 to find out their differences, performance for specific benchmarks, and performance for specific applications.
6/23/2025
Deepseek-V3.1 vs GPT-4.1
artificial intelligence
22 min read

Recently, you might have been hearing a lot about AI-driven chatbots, since they have been making significant strides to not just uplift your workflows but make it more smarter than ever. In this race of providing AI-driven convenience, we are witnessing a neck-to-neck competition between Deepseek V3.1 and GPT-4.1 to build global autonomy.
In this race of Deepseek Vs GPT, we are receiving rapid innovations and advancements every other day. From understanding, summarizing, and generating text, to now even being able to create desired visuals and or even understand the voice, both these AI models have completely transformed the way we used to function earlier.
Let's take a deeper look at both these AI models, Deepseek V3.1 and GPT-4.1, and understand how each of them works, evaluate both models' performance, learn about their best use cases, and eventually help you in deciding which one is best.
What is an LLM-powered Chatbot? And how is it transforming the world?
The LLM-powered chatbots are AI-driven, which integrate large language models that allow them to understand the provided input and generate responses that resemble how humans would react. These LLM-based chatbots work as smart assistants for tasks like support, tutoring, writing, and decision-making across industries.
With these LLM-powered chatbots, we are witnessing workflows becoming smart, intelligent, and optimized as ever. Where earlier we had to exercise more resources, time, effort, and intelligence for getting a task done, today we have these chatbots to handle these complex interactions single-handedly, making it more fast, precise, accurate, and reliable.
If we hear it in the words of Sam Altman (CEO of OpenAI) about how chatbots are transforming the world, he says:
“AI systems like ChatGPT are beginning to transform how we work, learn, and communicate—fundamentally reshaping the future of human productivity.”
So, from here, we can anticipate that these AI-powered chatbots are gearing up to further enhance workflows and redefine daily productivity.
Deepseek V3.1
DeepSeek-V3.1 is one of the latest models released that exhibits excellent reasoning, coding, and multilingual abilities. This model holds a 128K context window, which allows you to conveniently understand longer contexts, ensure complex problem solving, and generate precise text reflecting your requirements.
How does Deepseek V3.1 work?
DeepSeek-V3.1 has its particular architecture that works behind it to help it deliver the required functionality. Below, we have explained in detail how each component in this DeepSeek-V3.1 model works in collaboration to generate responses with all the elements that users expect.
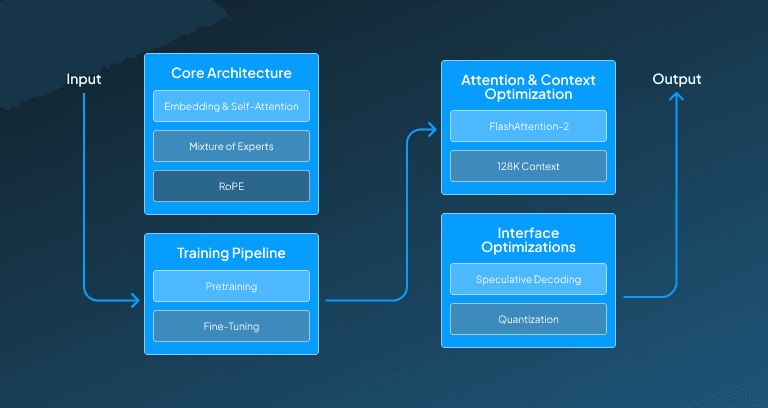
Core Architecture
The core architecture that helps DeepSeek-V3.1 deliver excellence has three major components that work together. This core architecture provides a strong base to this model, allowing it to compute efficient and accurate responses.
Step 1: Transformer Backbone Setup
The transformer backbone setup implements a decoder-only model that takes the provided input in tokenized form. These tokens are passed through embedding layers with a vocab size falling in the range of 100k-120k. Then, with the help of a multi-headed self-attention mechanism, the relationship between these tokens is computed, and the feed-forward network further transforms the features nonlinearly. As a result of this layer, we get the input transformed into contextualized token representations
Step 2: Mixture of Experts (MoE) Integration
Then, these contextualized tokens are assigned a particular expert through a gating network. The assigned experts of the token then further process these tokens in parallel, and finally, the results are combined, weighted by gating scores. This process helps in increasing the computation efficiency by 4 times.
Step 3: Rotary Positional Embeddings (RoPE)
With the step of rotary positional embeddings, we rotate the token embedding in a multi-dimensional space based on its position. These positions are calculated by using the sin and cos functions, which are like classic positional encodings. Then, these rotated positions are used by the attention mechanism to enable better understanding of the relative position of tokens in transformers. This layer can save relative positions for a 128K context without degradation.
Attention & Context Optimization
Through the process of attention and context optimization, this DeepSeek-V3.1 model generates responses with minimized latency and handles longer contexts of conversions, making it extremely reliable.
Step 1: Flash Attention-2 Implementation
To optimize the utilization of memory and processing speed, DeepSeek-V3.1 has a memory hierarchy optimization which works by which works by splitting attention matrices into smaller GPU SRAM-friendly tiles. By implementing this, it reduces frequent reads and writes to bandwidth memory, improving the efficiency and minimizing the latency. This approach minimizes frequent reads and writes to high-bandwidth memory (HBM), significantly reducing latency and improving efficiency. This makes it 2-4 times faster than a traditional transformer.
Step 2: 128K Context Handling
Also, for handling a context window of 128K tokens, the model integrates KV Cache Compression approach, such as low rank approximations for storing past token states more efficiently. Through this optimization approach, it reduces the VRAM need from 40GB to 24 GB, making it suitable for long text processing.
Training Pipeline
This DeepSeek-V3.1 training process is divided into two key phases, which include pretraining and training loop. This training procedure allows this model to demonstrate the required functionality and expected behaviour during the interaction.
Step 1: Pretraining
The pretraining phase can process a dataset of up to 10 TB of text, which could be from web content, books, code, and multilingual sources. This provided data then goes through This data undergoes rigorous filtering through deduplication and toxicity/quality classifiers, ensuring high-quality inputs. This training loop continues to use training loop utilizes a massive batch size of 4 million tokens, which are implemented through Megatron-style 3D parallelism that boosts computation efficiency, by using standard cross-entropy for nested token prediction.
Step 2: Fine-Tuning
In the step of fine-tuning, it implements supervised fine-tuning, in which it learns the required behaviour by training on over 100K+ human-written prompts and responses to align its outputs with expectations. Then Reinforcement Learning from Human Feedback (RLHF) is applied, in which a reward model is trained by using humans' rank outputs to establish preference rankings, and consequently, the model itself goes through Proximal Policy Optimization (PPO), to iteratively adjust the responses to maximize the reward scores. With this process, it helps DeepSeek-V3.1 deliver contextually accurate responses.
Inference Optimizations
By incorporating this step in its working, it ensures that the generated responses are not only rapid but also minimize errors. Through this, it also makes sure to optimize memory utilization by using a quantization approach.
Step 1: Speculative Decoding
This DeepSeek-V3.1 model uses speculative decoding to speed up inference. In its draft phase, it can generate 5-10 draft tokens. This model then verifies the token in parallel by accepting correct predictions and eventually correcting errors in a single pass. This helps in improving the throughput by 2.5x compared to traditional autoregressive decoding.
Step 2: Quantization
Then, this DeepSeek model uses 4-bit GPTQ quantization to uplift the model's efficiency. In this, it represents input in the form of weights compressed into 4-bit values through group-wise quantization. By doing so, it reduces memory requirements, enabling it to even run a 70B parameter model on a consumer-grade GPU while maintaining strong performance.
Parameters to Evaluate Deepseeks Performance
While DeepSeek-V3.1 is making wonders possible, by making the execution of tasks not only easy but also fast. However, to understand the performance of DeepSeek-V3.1 in depth, we have mentioned some of its key parameters in the table given below, which are considered to evaluate its performance.
Model Size | Large but efficient (likely MoE-based) | Highly Important |
|---|---|---|
Context Length | 128K tokens (best-in-class) | Highly Important |
Training Data | High-quality, multilingual, diverse | Critically Important |
Inference Speed | Faster than LLaMA-3 70B (optimized) | Highly Important |
Multilingual | Strong in Chinese and English | Important |
Safety & Alignment | RLHF + Content Filtering | Critically Important |
Hardware Efficiency | Runs on consumer GPUs (quantized) | Important |
RAG Support | Works well with 128K context | Moderately Important |
Cost Efficiency | Free and open weight | Highly Important |
By delivering such performance, DeepSeek-V3.1 excels across key performance metrics, as it offers a large yet efficient model with best-in-class 128K context length, rapid inference speed, and strong multilingual support. With its efficient training and hardware utilization, it stands out as a powerful and cost-effective LLM solution.
Evaluating Benchmarks of Deepseek-V3.1
There are some important benchmarks based on which researchers and engineers decide about the performance of any LLM model. To help you in building a well-rounded understanding, we have listed DeepSeek-V3.1's performance across some important benchmarks.
MMLU (Massive Multitask Language Understanding)
What It Measures:
MMLU is the benchmark that evaluates the general knowledge of an LLM model evaluates model across 57 subjects.
It checks the factual accuracy, reasoning, and comprehension of the responses in a zero-shot/few-shot setting.
Performance in DeepSeek-V3.1:
The DeepSeek-V3.1 shows a performance that is very competitive with what GPT-4 class models are exhibiting.
This model shows strong performance in technical domains like physics, math, and computer science due to quality training data.
GSM8K (Grade School Math 8K)
What It Measures:
With this benchmark, we evaluate the mathematical reasoning of the DeepSeek-V3.1 model.
This benchmark evaluates the responses of the model for grade-school to high-school level word problems.
Performance in DeepSeek-V3.1:
This Deepseek-V3.1 model shows accuracy greater than 90% for the GSM8K benchmark, allowing it to compete with GPT-4 and Claude 3.
This delivers this reliable performance to chain-of-thought (CoT) fine-tuning.
MATH (Competition-Level Math Problems)
What It Measures:
Through this benchmark, we evaluate the performance of the LLM solution for an advanced math problem that includes algebra, calculus, number theory, and proofs, whose difficulty level is more than GSM8K.
If the model shows limited capabilities for this benchmark, then it indicates that it can show limitations in technical fields.
Performance in DeepSeek-V3.1:
This DeepSeek-V3.1 has shown the ability to ensure results with about 40-50% accuracy, which indicates that it's close to GPT--4
Although this is still behind a specialized tool, it still shows appropriate performance for LLM.
HumanEval (Code Generation)
What It Measures:
This benchmark helps in evaluating the Python coding ability of the LLM models.
This makes it critical for developer tools so that they can be helpful for developers during the development process.
Performance in DeepSeek-V3.1:
For this particular benchmark, DeepSeek-V3.1 has shown about 80% enhanced performance for development purposes
This shows strong fine-tuning because of being trained on high-quality data.
FLORES (Multilingual Translation)
What It Measures:
This DeepSeek-V3.1 model shows capabilities to translate the response in 100+ languages, among the top languages we have English, Chinese, Hindi, and Spanish.
This parameter helps in evaluating the fluency, accuracy, and cultural nuance of the generated responses.
Performance in DeepSeek-V3.1:
DeepSeek-V3.1 shows amazing performance of interacting in major Strong in major languages like Chinese, Spanish, and French.
However, this might show lag in low-resource languages like Swahili and Bengali.
BIG-Bench (BIG-Bench Hard)
What It Measures:
With this BIG-Bench benchmark, we evaluate the model's capability to perform complex reasoning tasks like solving logic puzzles, sarcasm detection, and riddles.
Through this benchmark, we test general intelligence, not just memorization.
Performance in DeepSeek-V3.1:
This DeepSeek-V3.1 is expected to be close to GPT-4 but may be behind Claude 3 in some reasoning tasks.
This model delivers strongly in logical deduction, but might be weaker in abstract creativity.
TruthfulQA (Factual Accuracy & Hallucination)
What It Measures:
One of the most important benchmarks is to know that your desired model is generating factually correct responses without hallucination.
This test's factual grounding and avoidance of "confabulation."
Performance in DeepSeek-V3.1:
This model is more likely to perform better in terms of ensuring factual accuracy than most open models (e.g., LLaMA 3), but may be behind GPT-4.
This utilizes RLHF and retrieval augmentation to reduce the chances of errors in the responses.
Example Video:
Evaluating DeepSeek-V3.1 across key benchmarks with prompts covering general knowledge, math reasoning, advanced problem-solving, coding, multilingual understanding, and factual accuracy.
How Deepseek V3.1: Analyze
GPT-4.1
The GPT-4.1 model was released by OpenAI on April 14, 2025. Right after its introduction, this model has shown amazing multimodal capabilities by having a 1-million token context window. By holding these abilities, it offers improved instruction following, faster inference, and enhanced coding abilities, ultimately delivering uplifted performance. It outperforms GPT-4.5 in coding benchmarks and is available to ChatGPT Plus, Pro, and Team users.
How does GPT-4.1 work?
The GPT-4.1 model has its specialized architecture, which works in a particular way to cater rising needs of users. Just like its predecessors, it's built by using the transformer architecture, allowing it to ensure optimized performance, instruction-following, and multimodal capabilities. Below, we have explained in detail how this GPT-4.1 works to help you build a deeper understanding of it:
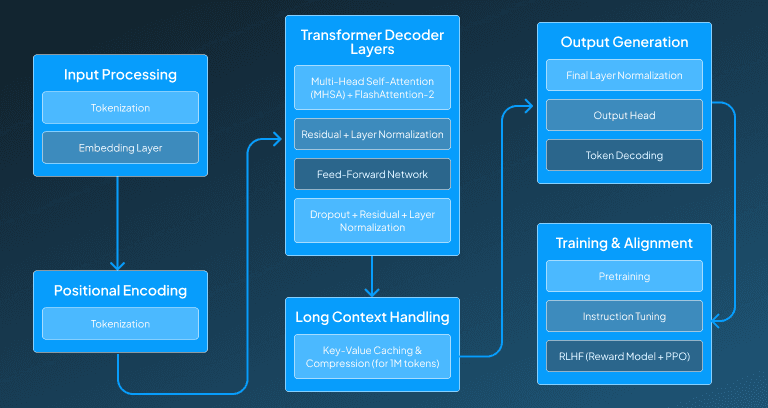
Input Processing
Right after receiving the input from the user, the GPT-4.1 model starts the procedure of processing the input. This process is further divided into two steps, which include tokenization and embedded layering.
Step 1: Tokenization
After receiving the input text it is initially broken down into smaller token using tokenizers like The input text is first broken down into tokens using a tokenizer like Byte-Pair Encoding or Tiktoken. This allows conversion of each word or subword in the sentence into a unique token ID.
Step 2: Embedding Layer
After assigning each word or subword a token ID, these tokenized words are then mapped to a dense vector known as embeddings. These embedding captures their semantics in high high-dimensional space. Then these vectors are further processed to carry out the desired task.
Positional Encoding
Once the process of tokenization and mapping of input into embedding form is completed, then these input tokens mapped in the form of dense vectors are further processed for positional encoding.
Step 1: Rotary Positional Embeddings (RoPE)
As the transformers lack the ability to sense word order, this GPT-4.1 model applies positional embeddings to address this limitation. Instead of absolute positional encodings, this RoPE captures relative positions between tokens, which makes it significantly efficient for very long sequences up to 1 million tokens.
Transformer Decoder Layers
The GPT-4.1 model has a lot of stacked decoder layers, it is possibly around 80+ in large-scale versions. Each of the layers has its subcomponent, which is explained below:
Step 1: Multi-Head Self-Attention (MHSA)
After positional encoding, each token attends to all previous tokens using scaled dot-product attention. This multiple attention heads help in learning different patterns simultaneously. By using optimized mechanisms like FlashAttention-2, the GPT-4.1 model extends speed and memory efficiency.
Step 2: Layer Normalization and Residual Connection
Then the output of attention is normalized and added to the input through a residual connection, which plays its role in preserving information and stabilizing training.
Step 3: Feed-Forward Network (FFN)
The normalized output is then taken to feed forward networks, which contain two linear layers with non-linear activation, which is usually GELU. Then it expands and comprises the input dimension to learn the complex transformations.
Step 4: Dropout, Residual, and Layer Normalization
We finally have the dropout mechanism to prevent the model from getting overfitted, and then we apply another residual connection and a normalization layer before passing the output to the next decoder block.
Long Context Handling
To ensure consistency and accuracy in the responses for a longer context, this GPT-4.1 model holds the ability to handle longer contexts, eventually help the model in generating responses that align well with the user query.
Step 1: Key-Value Caching and CompressionFor handling the long context of about 1 million tokens, this GPT-4.1 model uses key-value compression techniques. This helps in significantly reducing the memory consumption by approximating and compressing the stored attention states while preserving the contextual relevance.
Output Generation
Finally, to generate a comprehensive and reliable response that mentions all the requirements, we have the output generation layer, which is further divided into two steps: Final Layer Normalization and token decoding.
Step 1: Final Layer Normalization and Output Head
What happens under this step is that the last transformer layer output is normalized and passed through a linear layer known as the output head that projects it onto the vocabulary space, producing logits for each possible next token.
Step 2: Token Decoding and Sampling
Then the model chooses the next token by utilizing sampling strategies like greedy, top-k, or nucleus sampling. This GPT-4.1 sometimes might use speculative decoding, in which a smaller model introduces tokens that are verified by the full model for enhancing speed.
Training and Alignment
The last but one of the most important processes is to ensure proper training of the model so that the generated responses meet the expectations. This procedure of training is then divided into three steps, which include pretraining, instruction tuning, and Reinforcement Learning from Human Feedback (RLHF).
Step 1: Pretraining
The GPT-4.1 model has been trained on a large and diverse dataset of text and code, which mostly uses next-token prediction, with a cross-entropy loss function to ensure meaningful responses.
Step 2: Instruction Tuning
In order to deliver the most authentic and comprehensive responses, this GPT-4.1 model is further fine-tuned on curated datasets, allowing it to follow human instructions with more precision.
Step 3: Reinforcement Learning from Human Feedback (RLHF)
Through the implementation of RLHF, we have a reward model that evaluates multiple model outputs and eventually ranks them by preference. Additionally, this GPT-4.1 is fine-tuned by using Proximal Policy Optimization (PPO) to uplift its overall performance in terms of helpfulness, safety, and factual accuracy.
Parameters to Evaluate GPT-4.1 Performance
To help in getting a better overview of GPT-4.1 performance, we have evaluated it on some key parameters that will help you in determining that is model can assist you with your daily tasks. We have provided these parameters and what GPT-4.1 offers for it in the table given below.
Model Size | Large-scale architecture, optimized for performance; likely uses sparse MoE structure | Highly Important |
|---|---|---|
Context Length | Supports up to 1 million tokens (extended context, ideal for long documents) | Highly Important |
Training Data | Trained on high-quality, filtered, multilingual, multimodal datasets | Critically Important |
Inference Speed | Optimized for lower latency via kernel improvements and caching strategies | Highly Important |
Multilingual | Strong performance in English and competitive in major global languages | Important |
Safety & Alignment | Fine-tuned using RLHF and content moderation layers for safe and controlled outputs | Critically Important |
Hardware Efficiency | Available in optimized variants (e.g., GPT-4-turbo) that run efficiently on various GPUs | Important |
RAG Support | Performs well with RAG pipelines using extended context and embedding enhancements | Moderately Important |
Cost Efficiency | Used in OpenAI services like ChatGPT (GPT-4-turbo); significantly cheaper than GPT-4 | Highly Important |
By exhibiting such performance, the GPT-4.1 model is not just contributing a large context window, efficient inference, but also robust multilingual capabilities, enriching its overall accessibility around the globe. This makes this model highly reliable for diverse use cases.
Evaluating GPT-4.1 on Benchmarks
To better understand the ability of the GPT-4.1 model for specific use cases in daily life, we evaluate it on some key benchmarks. These benchmarks will help you in deciding that whether this GPT-4.1 model can execute the required task in a desired manner.
MMLU (Massive Multitask Language Understanding)
What It Measures:
With MMLU it enables the models' ability to answer queries related to general knowledge and reasoning.
This also helps in evaluating the model's factual accuracy, comprehension, and logical reasoning in zero-shot or few-shot settings.
Performance in GPT-4.1:
This GPT-4.1 exhibits the best performance for the MMLU benchmark and provides exceptional reasoning in the responses.
It is often ranked as one of the top publicly evaluated models for technical and humanities domains, as it's refined to deliver the best response.
GSM8K (Grade School Math 8K)
What It Measures:
This benchmark checks the mathematical problem-solving ability of the developed models.
This particularly focuses on assessing the ability of models to answer school-grade-level mathematical problems.
Performance in GPT-4.1:
GPT 4.1 has achieved about a 90% accuracy on GSM8K, making it comparable to GPT-4-Turbo and Claude 3 Opus.
With its chain of thought reasoning, it computes a step-by-step solution for your given mathematical problem.
MATH (Competition-Level Math Problems)
What It Measures:
The MATH benchmark checks the model's ability to solve advanced mathematical problems.
This includes assessing its ability to solve complex algebra, calculus, geometry, and number theory, beyond basic arithmetic problems.
Performance in GPT-4.1:
This GPT-4.1 model has shown about 50–60% accuracy, showing a better score but really perfect as of now.
It uses specialized mathematical models for decision making and has shown better performance than most of the general-purpose LLMs, especially when paired with structured prompting or tools.
HumanEval (Code Generation)
What It Measures:
This benchmark is particularly about assessing the code generation and development abilities of a model.
Through this benchmark, we can assess how useful a particular model is for developers and software assistants.
Performance in GPT-4.1:
The GPT-4.1 models stand among the top-ranked models for code generation, as it passing score isbouit 85%+ when assisted by CoT or system prompts.
This GPT-4.1 model exhibits strong zero-shot and few-shot coding capabilities across Python and other languages of your choice when prompted in a proper manner.
FLORES (Multilingual Translation)
What It Measures:
Through FLORES benchmark, the ability of a model to translate or interact in multiple languages is tested.
This helps in evaluating how effectively, fluently, and comprehensively a model can communicate in multiple languages.
Performance in GPT-4.1:
The GPT-4.1 shows impressive abilities for generating responses in multiple languages.
While it performs amazingly in low-resource languages, models like Mistral or specialized translators may outperform it in niche-specific scenarios.
BIG-Bench (BIG-Bench Hard)
What It Measures:
Through this BIG-Bench benchmark, the model's ability to perform logical reasoning, abstract problem-solving, and general intelligence is assessed.
This benchmark actually tests the model's ability to answer questions requiring general knowledge beyond memorization or pattern repetition.
Performance in GPT-4.1:
GPT-4.1 has shown excellent scores for the BIG-Bench benchmark Hard by scoring high on logic puzzles, abstract reasoning, and multi-step problems.
It's often ranked just below Claude 3 Opus in raw performance, but it performs better than most of the open models and older GPT versions.
TruthfulQA (Factual Accuracy & Hallucination)
What It Measures:
One very important benchmark is about knowing the model's accuracy; therefore, with this benchmark, we evaluate the truthfulness of AI responses.
This helps in finding out the model's tendency to generate incorrect responses by measuring factual grounding.
Performance in GPT-4.1:
The GPT-4.1 is one of the most trustworthy, truthful models because of its improved RLHF and alignment tuning.
These models rarely hallucinate while generating responses and can efficiently perform tasks like citing or reasoning when given proper grounding.
Example Video:
Evaluating GPT-4.1 across key benchmarks with prompts covering general knowledge, math reasoning, advanced problem-solving, coding, multilingual understanding, and factual accuracy.
ChatGPT 4.1: Benchmark Test
Deepseek-V3.1 Vs GPT-4.1: Who is winning?
Whether it's DeepSeek-v3.1 or GPT-4.1, both have their specialized abilities for specific use cases. Below we have listed some use cases and informed you how both perform for it, and which offers the best performance, to help you in deciding on the implementation.
Customer Support Chatbot | Fast and reliable responses, strong technical FAQs, especially in Chinese | More fluent, context-aware, emotionally aligned conversations across languages | GPT-4.1 |
|---|---|---|---|
Academic Tutoring (STEM Focus) | Excels in physics, math, and computer science explanations with CoT | Stronger at step-by-step reasoning and answering across broader academic topics | GPT-4.1 |
Coding Assistant (Python/JS) | Very competitive in Python, supports CoT, trained on clean data | Superior code generation, debugging, and docstring generation across multiple languages | GPT-4.1 |
Legal/Policy Drafting | Reasonably accurate, strong formatting, less nuanced reasoning | High-level reasoning, structured, better legalese, and policy compliance | GPT-4.1 |
Chinese Language Teaching App | Top-tier performance in Chinese language comprehension, grammar, and cultural alignment | Strong but may underperform DeepSeek in the complex Chinese context | DeepSeek-V3.1 |
Language Translation | Great in major languages (Chinese, French, Spanish); weaker in low-resource languages | Better fluency, nuance, and support for 100+ languages, including low-resource ones | GPT-4.1 |
Math Homework Solver (GSM8K) | Excellent at grade-school problems; over 90% accuracy | Equal or slightly better accuracy, more consistent chain-of-thought explanation | Tie |
Competitive Exam Prep (MMLU) | Great in technical domains; slightly less generalized coverage | More balanced and diverse subject knowledge and reasoning | GPT-4.1 |
Business Email Generator | Concise and professional tone, may lack emotional range | Well-structured, nuanced, and polite emails with better alignment | GPT-4.1 |
Research Summarization Tool | Accurate for technical articles; slightly robotic summaries | More abstract, fluent, and context-sensitive summarization | GPT-4.1 |
Voice Assistant (Low Latency) | Optimized for faster inference; great for edge devices | Requires more compute, slightly slower in local setups | DeepSeek-V3.1 |
Fact Checker Tool | Performs better than most open-source models | Industry-leading factual grounding with minimal hallucination | GPT-4.1 |
While GPT-4.1 excels in performing general-purpose, enterprise, creative, and reasoning-intensive tasks, DeepSeek is also giving tough competition by ensuring fast responses and open-source apps, making it preferable for applications that prioritize rapid responses. If you are a startup, then DeepSeek is better for you because of the open access, but if you are a company that needs precision, then you should consider GPT-4.1.
Conclusion
Both DeepSeek-V3.1 and GPT-4.1 are powerful and distinct large language models. Where GPT-4.1 is offering exceptional performance in reasoning, creativity, enterprise-level use case, or for multilingual communication, DeepSeek-V3.1 is not staying behind in the race as it stands. So, if you are a startup or a developer finding an accessible, fine-tunable LLM, then in this case, DeepSeek-V3.1 is the ideal choice for you.
Contrary to this, if you are a business requiring top-notch precision in legal, academic, or creative outputs, then you should consider GPT-4.1. Ultimately, the right choice is totally dependent on your particular expectations from the use case. But by implementing any of these models for your particular solution, you can witness your workflows getting optimized and becoming efficient.
Curious which model best fits your business needs, DeepSeek-V3.1 or GPT-4.1? Why not find out with a quick session? Book a free meeting with our experts at Centrox AI and get personalized guidance tailored to your use case.

Muhammad Harris
Muhammad Harris, CTO of Centrox AI, is a visionary leader in AI and ML with 25+ impactful solutions across health, finance, computer vision, and more. Committed to ethical and safe AI, he drives innovation by optimizing technologies for quality.
Do you have an AI idea? Let's Discover the Possibilities Together. From Idea to Innovation; Bring Your AI solution to Life with Us!
Your AI Dream, Our Mission
Partner with Us to Bridge the Gap Between Innovation and Reality.