Fine-tuning Open-Source LLMs with Hugging Face: A Complete Step-by-Step Guide
Learn the step-by-step guide to fine-tune open-source LLMs with Hugging Face, and get to know about its benefits, limitations, and some industry-available applications.
6/11/2025
Fine-tuning Open-Source LLMs with Hugging Face
artificial intelligence
14 min read

AI-powered innovations are completely changing traditional workflow practices, and in this race to introduce helpful advancements, we have witnessed some really impressive solutions, which are making life easier. Here, getting a particular solution addressing your specific needs by training an open-source LLM has made the path convenient and accessible.
Instead of making the efforts from scratch, these open-source model helps in saving time by providing a built-in model which has basic functionalities. This basic open-source model can be further fine-tuned to carry out a particular domain-specific task of your choice.
With our article, we help you understand an open-source LLM and provide you with step-by-step instructions for training it to carry out the expected task. We will also discuss the benefits and limitations of training an open-source model.
Understanding LLM’s
Large Language Models(LLMs) are AI systems that have been trained on a large amount of dataset that allows them to understand the underlying intent and generate text that resembles humans. They function by learning and understanding the complex patterns within books, articles, or websites to generate responses that appropriately answer questions, write coherent text, and translate in a particular language. Because of having billions of parameters, they hold the ability to handle complex language tasks, to make AI-driven interaction more enhanced and realistic.
What is Open-Source LLM?
An open-source LLM is are model whose code bases and training dataset are available publicly so that it can be used by anyone for modification and improvement for their specific use case. Contrary to traditional proprietary models, which are owned by companies, open-source LLMs enable transparency, collaboration, and community-driven development, allowing developers and researchers to tailor the LLM according to their needs.
Step-by-Step Guide to Fine-Tune Open-Source LLMs with Hugging Face
These open-source model can be used by anyone to fine-tune and use them according to their specific demands. However, there are a few steps that need to be followed for fine-tuning an open-source LLM in order to customize it for a particular application. Below, we have provided the required step-by-step guide for fine-tuning open-source LLM to help you in the process:
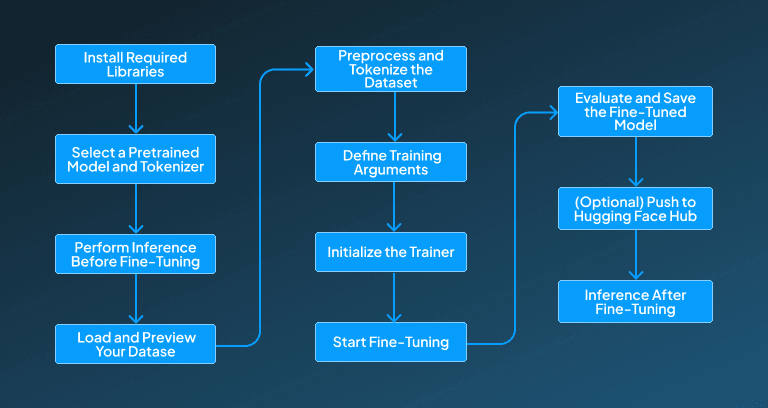
Step 1: Install Required Libraries
Explanation:
The process of fine-tuning is initiated by installing essential libraries. The Hugging Face’s libraries, like transformers and datasets, provide the required access to models and datasets, whereas the accelerate library handles the hardware optimization, like working to optimize the GPU usage, and the bitsandbytes library enables memory-efficient training by utilizing quantization. Here, a GPU environment is very strongly recommended to speed up the process.
Code:
Step 2: Select a Pretrained Model and Tokenizer
Explanation:
Training a model from scratch is a very resource-intensive task that consumes a lot of time and computational resources. So it's better to start the process of preparing a customized solution with a pretrained open-source model like GPT-2, Falcon, Mistral, etc. As these pretrained models hold the ability to understand the general language pattern, they can be further fine-tuned by training them on specific data to get a specialized task done.
Code:
Step 3: Perform Inference Before Fine-Tuning
Explanation:
In this step, we test how the base model responds to a simple prompt before any training. This helps establish a performance baseline. Comparing this output with post-training results shows how much the model has improved.
Code:
Step 4: Load and Preview Your Dataset
Explanation:
By utilizing Hugging Face's dataset library, we can load the relevant dataset to fine-tune the model according to your set goal. You can also use a local dataset, which could be in .txt or .csv format. By previewing some of the entries, you can ensure that the provided data’s structure aligns well with the expectations of the model you are about to train.
Code:
Step 5: Preprocess and Tokenize the Dataset
Explanation: The LLMs can understand numerical inputs, therefore, the raw textual input needs to be converted into token IDs. So, during this step, the long inputs are truncated, whereas the shorter ones are padded to apply consistent formatting throughout. This step ensures that the model can process inputs in a standardized format regardless of the text length they possess.
Code:
Step 6: Define Training Arguments
Explanation: The next important step in the process of fine-tuning an open source model is to define the training arguments. Defining training arguments allows you to control the whole training process, eventually helping in meeting the expected goals. Under this step, you can specify the batch size, learning rate, number of epochs, where to save the model, how often to evaluate, and other parameters. This step is very critical for getting the right results for both training speed and model performance.
Code:
Step 7: Initialize the Trainer
Explanation:
After defining the training arguments, the next step in the process is to initialize the trainer. The Hugging Face’s trainer class simplifies the training workflow by handling data loading, forward/backward passes, evaluation, logging, and checkpointing. This trainer then manages the next tasks under it.
Code:
Step 8: Start Fine-Tuning
Explanation: Once the setup is completed, the process of training is started. During this step, the models start adjusting their weights by using the dataset that you have provided. The quality of fine-tuning a model depends directly on the epochs as well as the quality of data you feed to it for training. As enhanced fine-tuning of model results in computation of more improved outputs for the designated task.
Code:
Step 9: Evaluate and Save the Fine-Tuned Model
Explanation:
When the process of training is completed, we initiate evaluating the model's performance on the validation data to ensure that it has learned to perform the expected task. After this, the model and the tokenizer are saved so that they can be reloaded later on for inference or deployment purposes. This helps in preserving the trained parameters for future use.
Code:
Step 10: (Optional) Push to Hugging Face Hub
Explanation:
If you are willing to share your fine-tuned model or access it through the cloud, then you can push it on Hugging Face Hub with public or private access. This provides a more convenient environment for collaboration, versioning, and deployment without needing local storage.
Code:
Step 11: Inference After Fine-Tuning
Explanation:
Here, we load the fine-tuned model and run the same prompt used earlier to observe any changes in its response. This step demonstrates how well the model has adapted to the new data. It enables a direct comparison with the base model’s output to evaluate fine-tuning impact.
Code:
Popular Industry Application Built with Open-source LLMs
Today, many industries are using open-source LLMs for customizing and developing their solution for some specific use case. This approach not only saves time and effort that would be consumed for developing and training a solution from scratch. Below, we have mentioned a few industry available examples that have utilized open-source LLMs for developing a niche-specific solution:
BloombergGPT
Bloomberg GPT is developed to handle financial tasks like document classification, sentiment analysis, and answering simple questions from the provided financial report. It's further customized on both general and domain-specific financial data. This tailored solution is developed using open-source frameworks like PyTorch.
Notion AI
This is an AI-driven application used for assisting users in generating summarized notes, content, and rewriting text. It can also be used for automating repetitive writing tasks within the Notion workspace. This application was initially powered by open-source models like GPT-J and GPT-Neox before integrating commercial API’s.
Mistral-Based Chat Assistants
Mirstral-based chat assistants are some applications introduced to handle general-purpose queries. This AI assistant can be used for internal knowledge bases, customer support, and developer copilot because of their open weights and efficient performance. This Mistral chat assistant is based on the Mistral 7B model, which allows it to exhibit the desired performance.
Private ChatGPT Alternatives (e.g., LM Studio, OpenChat, Ollama)
LM Studio, Openchat, and Ollama are some tools that organizations and individuals can use for running local/ private AI chatbots without depending on OpenAI’s API. These applications are based on LLaMA, Mistral, Zephyr, and GPT-J models, which enable it to contribute a secure environment and function as a local productivity assistant.
Hippocratic AI
Hippocratic AI is an AI-powered healthcare assistant developed by using open-source models. This AI healthcare application can be used for patient communication, triaging, and medical Q&A as it's developed by fine-tuning the open-source model on more medical-specific training data and safety protocols.
Haystack by deepset
Haystack by deepset is an open-source search engine that allows its users to make enterprise-grade search, along with helping you in providing a question-and-answer system that could answer all the queries asked by using the internal documents. This Haystack delivers the required performance by using open-source LLMs in combination with RAG.
TabbyML or CodeGeeX
TabbyML or Codex are some alternatives to GitHub Copilot; these applications offer features like auto-complete, suggestions, or code debugging, making them ideal for companies that want Copilot-like features without sharing code externally. These tools are based on models like StarCoder, CodeGen, or LLaMa variants, which help provide a smart assistant to developers.
Benefits of Training Open-Source LLM
The training of open-source LLMs has gained popularity among developers, startups, and enterprises as it saves time and resources that would be required for development from scratch. These open-source models offer more flexibility, transparency, and control, as you can fine-tune them according to your specific expectations. We have listed some of the major benefits that fine-tuning open source elements can contribute:

• Customization for Specific Tasks
One of the most important benefits that fine-tuning of open-source elements contributes is the ability to tailor a generic LLM to ensure excellent performance for domain-specific tasks. This makes it easier for industry to develop their customized solution for handling a specific task, for understanding legal documents, customer service, or scientific writing, as these models perform better as they can understand the context and terminology.
• Cost Efficiency
Instead of relying on paid APIs from commercially available models, these open-source LLMs can be utilized and fine-tuned to carry out the desired task. They can be deployed at scale with reduced costs. Making the adoption and fine-tuning of open-source models a very appropriate choice for the application of startups and enterprises with heavy inference loads.
• Data Privacy and Control
These open-source models can be executed locally or in a secure cloud environment, making sure that sensitive data is always under control. It makes these open-source fine-tuned solutions very valuable for industries like healthcare, law, finance, and government services, because for solutions in these spaces, data protection is very critical.
• Transparency and Debugging
With the implementation and fine-tuning of an open-source model for your specific industry application, you get full visibility into how the model is structured, trained, and how it behaves. Additionally, this contributes to easing decision-making while auditing, tracing bugs, and reducing hallucination and biases as compared to the commercially available models.
• Offline Accessibility
Once these open-source models are fine-tuned, they are ready to be deployed without an internet connection. This makes it ideal for remote deployments, embedded systems, or environments that have limited access to internet connectivity.
• Community Collaboration and Ecosystem
As these open-source projects are provided by credible developers, researchers, and contributors, they promote the overall growth of the community. These open-source tools help industries as well as individual developers, as they can benefit from the shared tools, pre-trained checkpoints, datasets, and best practices, reducing the development time and effort.
• Regulatory Compliance
Utilizing and controlling the open-source model makes it easier for developers and experts to align its performance with regulations like GDPR, HIPAA, or internal compliance frameworks. This enables you to have control over using the data, processing it, alongside deciding how long you want to retain it.
Limitations of Training Open-Source LLM
Although fine-tuning open-source large language models (LLMs) offers flexibility and control, it also holds several challenges. The process of fine-tuning can get technically demanding, it requires high-end computational resources, a complex setup, and maintenance. Therefore, it's important to plan ahead of these limitations to ensure efficient performance from this open-source model.

• High Computational Requirements
Training or fine-tuning any large language model requires enough hardware resources like GPUs, TPU’s or large-scale cloud infrastructure to ensure smooth execution. Without having access to high-performance computing, the execution of processes can get slow, inefficient, or infeasible for small teams and individuals.
• Significant Memory and Storage Needs
LLMs might have billions of parameters that need tens to hundreds of GBs of memory and disk space. Therefore, storing these large models, checkpoints, and training datasets might strain the local systems or might cause an increase in the additional cloud costs.
• Complex Setup and Expertise Needed
The fine-tuning and deployment of open-source LLMs also requires a strong understanding of machine learning, tokenization, data processing, distributed training, and optimization core concepts. A newcomer or a non-technical user might struggle to fine-tune a model because of not lack enough knowledge.
• Long Training Time
Training or fine-tuning of LLM is a time-consuming process, regardless of how good your hardware resources are. As training process can take hours or days. This process involves steps like hyperparameter tuning, checkpointing, and error handling, which further increases the time consumption and the complexity, especially when we are experimenting with different configurations.
• Limited Out-of-the-Box Performance
Open-source LLMs might lack the ability to be polished or optimized like commercially available models. Because of this, their outputs might need post-processing, prompt engineering, or additional training in order to achieve the expected performance for production tasks.
• Biases and Ethical Risks
As the open-source models are often pre-trained on public internet data, this might cause it to contain harmful biases, misinformation, or toxic content that might compromise the output’s quality. So, implementing an open-source model without carefully curating or debiasing it may result in carrying forward these risks to the desired solution.
• Lack of Ongoing Support and Updates
Unlike the commercial models, which continuously offer improvements and updates, these open-source models depend on community maintenance, which might cause some pf the models to become outdated if they are not actively supported by the group of developers or researchers.
• Security and Safety Concerns
Implementing an open-source model can involve risks like harmful content generation or manipulation of information, as some of these might be poorly monitored or unchecked. Therefore, it is very critical to have a built-in safeguard, a fine-tuned open-source model to prevent such higher risks that could affect the performance as well as the reliability of the model.
Conclusion
Fine-tuning open-source LLMs with Hugging Face opens doors to endless possibilities, as it helps in customizing models for domain-specific use cases, to provide full control over data privacy and infrastructure. While the fine-tuning of open-source models holds a lot of benefits, but here it’s equally important to be mindful about the technical challenges, resource demands, and ethical responsibilities involved within the process.
If you’re developing a domain-specific chatbot, enhancing search systems, or powering intelligent automation, the open-source models provide a route to empowering you to innovate freely and cost-effectively. By having the right setup, tools, and strategy, your organization can push the boundaries of LLMs to unlock their fullest potential while avoiding the limitations of closed AI ecosystems.
Hugging Face and the other open-source ecosystems provide everything that you might need to begin this journey of preparing a customized solution, which can be empowering for your business, but only if you have implemented it correctly.
Feeling Confused about where to begin or how to align your LLM strategy with real business value? Book your session right away with our experts at Centrox AI today and turn your vision into a scalable, intelligent solution.

Muhammad Haris Bin Naeem
Muhammad Harris Bin Naeem, CEO and Co-Founder of Centrox AI, is a visionary in AI and ML. With over 30+ scalable solutions he combines technical expertise and user-centric design to deliver impactful, innovative AI-driven advancements.
Do you have an AI idea? Let's Discover the Possibilities Together. From Idea to Innovation; Bring Your AI solution to Life with Us!
Your AI Dream, Our Mission
Partner with Us to Bridge the Gap Between Innovation and Reality.