Reducing LLM Hallucinations with Knowledge Graph Integration
Gain understanding about LLM hallucination by learning its causes, effects, and how integrating knowledge graphs can help reduce it.
7/7/2025
Reducing LLM Hallucinations
artificial intelligence
9 min read

LLMs and their applications have been making significant strides in introducing applications that are bringing useful automations to make life easier. With each passing day, we have been observing growing interest and reliance among people on these LLM-powered tools. But with all these advancements, the major challenge that disrupts the interaction and reliability of the tool is the possibility of receiving hallucinated responses.
By reducing the occurrence of hallucinations in LLM responses, we can enhance user experience and make their workflows more optimized and efficient. An LLM tool with reduced hallucination helps in producing meaningful, validated outputs, which makes the execution of the task faster and intelligent.
With our article, we will help you understand what are hallucinations in AI, their causes, effects, and how we can reduce hallucinations in LLM responses through graph integration. By learning about these important aspects, we can plan ahead to avoid hallucination in LLM responses.
What is Hallucination in LLM responses?
In large language models (LLMs), hallucination occurs when the models start generating factually incorrect information or provide made-up information. Although the generated response might sound confident, it could be giving false details, inventing data, or misrepresenting facts due to limitations in understanding and reasoning.
Hallucinations in LLM responses are a major reason for concern, especially if these LLMs are applied for applications like healthcare, education, and law, where accuracy and authenticity are critical. This aspect is endorsed by the statement of Sam Altman( CEO of OpenAI), who says:
"The biggest challenge with these models is that they can confidently state things as if they were facts that are entirely made up."
Hallucination stands as a major challenge that compromises the reliability of its responses. Therefore, it's extremely important to develop an LLM-driven solution that generates meaningful responses without hallucinating.
Reasons for Hallucination in LLMs
Before learning about ways to reduce hallucinations in LLM's response, it's essential to understand the reasons that cause it. By learning about the reasons, we can gain knowledge to plan a solution for reducing it. For your understanding, we have listed some of the reasons that lead LLMs to generate responses with hallucination:
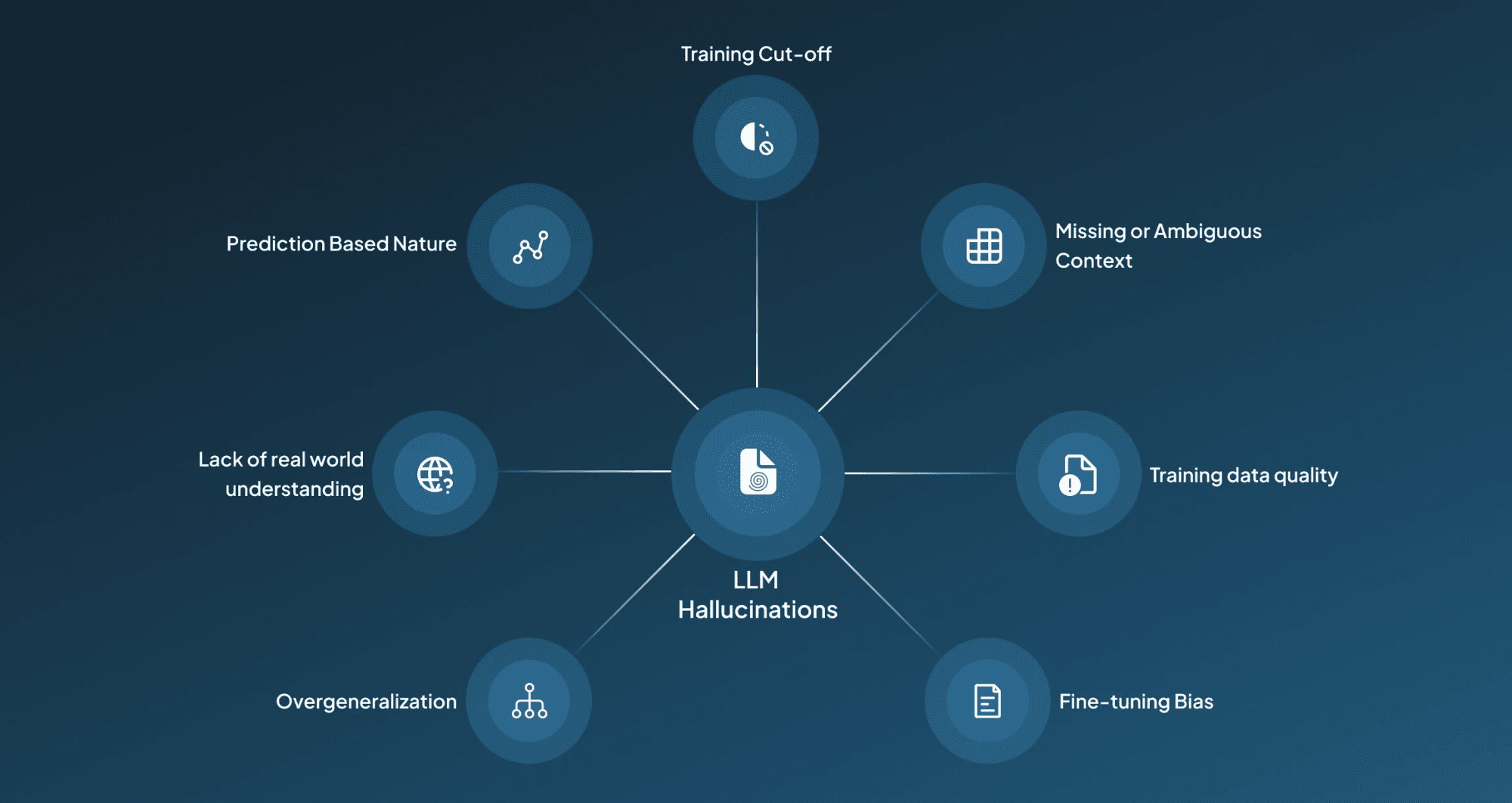
1. Prediction-Based Nature
“Studies have shown that the next token-based prediction nature of LLM models can be fundamentally flawed, as even teacher-forcing setups can fail to learn an accurate next-token predictor in the first place. This indicates that when a model is optimized on only the next token prediction, it can confidently generate believable-sounding next tokens, leading to hallucination in responses, especially for applications where deeper reasoning is required.” (Gregor et al., 2024)
2. Lack of Real-World Understanding
The LLMs generally do not hold the true ability to understand and reason the asked query; they work by understanding the complex training data pattern and ultimately generate responses mimicking the knowledge base. As these responses are not generated on actual comprehension of facts or logic, this might result in LLM generating hallucinated responses.
3. Training Data Quality
"Research has indicated that over 60% of errors in conversational benchmarks are due to the hallucinated content present in the training data itself, and not because of the model architecture. This shows how poor data quality can generate hallucinated responses, which compromises its credibility and reliability." (Nouha et al., 2022)
4. Missing or Ambiguous Context
In scenarios where the provided prompt misses the required detail or is ambiguous, the LLM starts filling the blank with assumption-based information and might generate a fabricated response, which could be misleading.
5. Overgeneralization
"Recent studies have brought forward how overgeneralization in LLMs can contribute to the generation of hallucinated responses, especially when providing summarization tasks. Researchers highlighted that LLM often generates false or hybrid responses when internal knowledge conflicts with input, indicating that overgeneralization can be a major source of hallucination." (Jongyoon et al., 2024)
6. Fine-Tuning Bias
If the data provided for fine-tuning the LLM response emphasizes fluency or user satisfaction rather than prioritizing factual accuracy, then it might generate output that focuses on sounding right over being right. Also, supervised fine-tuning on unfamiliar (new) facts not only slows learning but directly increases hallucination rate as models struggle, sometimes even forgetting earlier knowledge. (Zorik et al., 2024)
7. Training Cutoff
If the model's knowledge beyond a specific date is frozen, it might start confidently generating outdated, incorrect, or misleading responses for queries related to recent events and developments.
What are the Effects of Hallucination
An LLM generating hallucinated responses can become a major concern, especially if it's deployed for applications like healthcare, legal, or educational purposes. This LLM with hallucinatory response can eventually contribute to raising the following concerns, which are mentioned below:

1. Loss of Trust
If the LLM-driven tool predominantly starts generating factually incorrect hallucinated responses, then it may lose users' confidence over time. As fabricated responses compromise the quality of their work, they might end up spending more time correcting them.
2. Misinformation Spread
The generated hallucinated content can be mistaken for fact and may propagate false information, which is extremely concerning, especially in sensitive domains like news, healthcare, or education.
3. Poor Decision-Making
As these hallucinated LLM responses are not evidence-backed, it might be a fabricated decision. So, reliance on such incorrect outputs can lead to flawed decisions in business, legal, academic, or medical settings, which might disrupt the operation.
4. Reputational Damage
LLMs, which are deployed for handling enterprises or industries' workload, might affect the brand's credibility if the responses received by them show severe factual errors or fabrications. This leads to a significant downfall in users' trust and damages their reputation in the market.
5. Legal and Ethical Risks
An LLM generating misinformation may result in defamation, privacy violations, or non-compliance with regulations, potentially triggering legal consequences and raising ethical risks.
How to reduce hallucinations with knowledge graph integration?
Knowledge graph integration minimizes hallucinations in LLM responses by grounding these responses in structured, factual data. This works by linking entities to trusted sources and guiding generation on the retrieved graph facts, which helps the model in generating more accurate responses. Below, we have provided a detailed breakdown of how knowledge graph integration functions to reduce hallucination in the LLM responses:
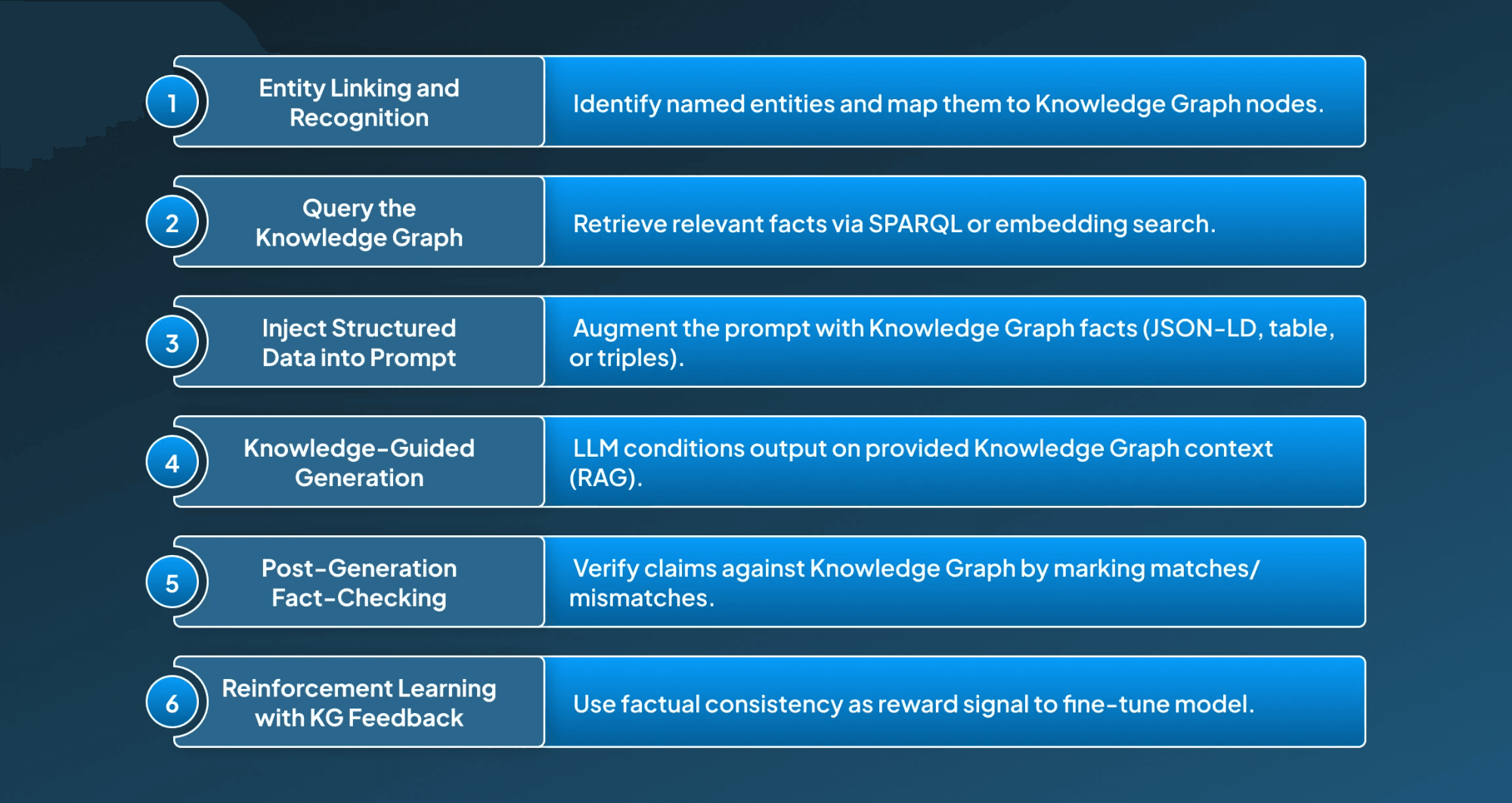
1. Entity Linking and Recognition
By using Named Entity Recognition (NER), we can identify the key entities in the input query and then eventually link them to corresponding nodes in the knowledge graph. This helps in keeping the response consistent with the factual data, significantly reducing hallucinations.
2. Query the Knowledge Graph
After this, convert the user query into a formal query in SPARQL or use an embedding-based KG search to help in retrieving relevant up-to-date facts that are related to the linked entities. This helps in aligning the responses with real-world graph knowledge-based relations.
3. Inject Structured Data into Prompt
Then we augment the model’s prompt with the derived knowledge graph(KG) facts utilizing the structured input formatting (e.g., JSON-LD, table-form summaries, or natural language rephrasing of triples). This helps in promoting factual accuracy and generating coherent reasoning as structured facts support logical flows.
4. Knowledge-Guided Generation
By using a retrieval-augmented generation (RAG) driven pipeline, in which the LLM conditions its output on the provided knowledge graph(KG) context. This encourages the model to stay consistent and limited to generating responses that closely relate to factual data.
5. Post-Generation Fact-Checking
After knowledge-guided generation, the generated responses are verified through fact-checking. This module verifies the output entities or claims against the knowledge graph(KG) to indicate or correct hallucination.
6. Reinforcement Learning with KG Feedback
By fine-tuning the LLM response using Reinforcement Learning from knowledge graph(KG) Feedback (RLKGF), in which reward signals are based on factual consistency with knowledge graph entries. This not only optimizes the generation behaviour but also improves adaptability, allowing the model to learn from an evolving knowledge graph.
Challenges of Building a Knowledge Graph
Although through integration of knowledge graph we can significantly improve the factual grounding of large language models, the process of building and maintaining a high-quality knowledge graph involves several technical and operational challenges. Below we have mentioned some key areas that need special consideration:
1. Data Collection and Cleaning
Creation of reliable knowledge graph initiates with gathering top-quality data from reliable sources. This step often requires rigorous filtering, deduplication, and normalization to eliminate noise and inconsistencies that could effect the performance.
2. Entity Disambiguation
Its is extremely important to correctly identify and link entities, particularly those with similar names or multiple meanings. As errors in this step can lead to incorrect relationships and generate misleading outputs.
3. Maintaining Accuracy and Relevance
As knowledge is continuously evolving, therefore it is essential keep a knowledge graph accurate and up to date according to the rising trends and demands, so that it generates relevant responses.
4. Handling Heterogeneous and Conflicting Data
Knowledge graphs often pull from diverse data formats and sources. Integrating this information while resolving conflicts or ambiguity requires sophisticated semantic modeling and validation.
5. Need for Human Oversight
Despite automation, human expertise remains essential for verifying data integrity, resolving edge cases, and ensuring that the graph supports trustworthy LLM grounding.
From Insight to Impact
Reducing hallucinations in Large Language Models is critical for building a trustworthy AI system, especially in knowledge-sensitive domains. Integrating knowledge graphs provides a powerful solution by grounding responses in structured, verified information.
From entity recognition and KG querying to prompt augmentation and reinforcement learning with factual feedback, each step enhances factual consistency and minimizes the risk of fabricated content. This fusion of symbolic reasoning and language generation not only boosts reliability but also improves interpretability and traceability. As LLMs continue to evolve, knowledge graph integration offers a promising path toward making AI responses more accurate, dependable, and aligned with real-world knowledge.
Are you ready to move beyond just introducing impressive language generation by building a trustworthy AI solution with uplifted accuracy? Then get in touch with our expert engineers at Centrox AI to discuss your concerns so that you can stay ahead in this ever-evolving market.

Muhammad Harris
Muhammad Harris, CTO of Centrox AI, is a visionary leader in AI and ML with 25+ impactful solutions across health, finance, computer vision, and more. Committed to ethical and safe AI, he drives innovation by optimizing technologies for quality.
Do you have an AI idea? Let's Discover the Possibilities Together. From Idea to Innovation; Bring Your AI solution to Life with Us!
Your AI Dream, Our Mission
Partner with Us to Bridge the Gap Between Innovation and Reality.