What is LLMOps and Why It’s Essential for Scalable AI Operations?
Learn about LLMOps, how its different from MLOps, its role in scaling AI operation, along key benefits and limitations.
8/18/2025
What is LLMOps
artificial intelligence
10 min read

AI and its innovative applications are emerging as indispensable elements that businesses can no longer ignore. With their LLM-based application for business, they are not just enabling convenience but also driving both work and cost efficiency for everyday processes.
Here, LLMOps is functioning to power these high-end LLM applications, so that they continue to work smoothly. This LLMOps handles the whole cycle for LLM from model selection to the feedback loop under its umbrella. By managing these responsibilities, it ensures scalability, agility, compliance, and safety, with significantly reduced cost, while the LLM runs in execution.
In this article, we will help you build your initial understanding of LLMOps, how this is different from MLOps, It's contribution to scalability. We will also be exploring how LLMOps work, some key tools for it, and break down its benefits and limitations, so you can make informed decisions about adopting it.
What is LLMOps?
Large Language Model Operation is a specific discipline of MLOps (Machinel learning Operations) that is focused on deploying, managing, monitoring, and optimizing the large language models (LLMs) that include GPT, Claude, LLaMA, etc., in production environments.
How is LLMOps different from MLOps?
LLMOps is an evolution that happened from MLOps to precisely address the challenges faced by LLMs. In the table given below, we have mentioned the core aspects that differentiate LLMOps from MLOps:
Model Types | Traditional ML models (e.g., regression, classification, decision trees,) Neural networks, and CNN | Large Language Models (e.g., GPT, LLaMA, Claude) |
|---|---|---|
Development Focus | Data preprocessing, training, validation | Prompt engineering, fine-tuning, retrieval-augmented generation (RAG) |
Deployment | Deploying custom-trained models | Using pre-trained models via APIs or hosting huge models efficiently |
Cost & Resources | Typically less resource-intensive | High compute and memory requirements (GPU-heavy) |
Monitoring Needs | Model accuracy, drift, and retraining triggers | Output quality, hallucinations, prompt drift, latency |
Optimization | Hyperparameter tuning, data pipeline tuning | Prompt tuning, quantization, and adapter models (e.g., LoRA) |
Human Feedback | Often limited to offline labeling | Continuous feedback (e.g., thumbs up/down, RLHF) |
Tooling | ML pipelines (e.g., MLflow, Kubeflow) | LLM-specific tools (e.g., LangChain, Weights & Biases with LLMOps plugins) |
So, from the above table, we can conclude that the MLOps are responsible for managing the ML pipeline from data to deployment. The LLMOps function to adapt those principles to address the unique challenges of LLM, which include prompt management, hallucination control, and cost-heavy deployments.
Why are LLMOps Essential for Scalable AI?
LLMOps plays a very essential role in scaling AI solutions that depend on Large Language Models( LLM). It can be considered the backbone for such AI solutions. As LLMOps ensures structured workflows from prompt to model management, enabling smooth iteration and reducing the error risk.
Furthermore, LLMOps proactively works to ensure compliance with safety standards, which helps in reducing the feedback loops and occurrence of untrustworthy AI behaviour. Therefore, LLMOps contributes to enhancing scalability by introducing automation, consistency, and observability across the LLM lifecycle. Demetrios Brinkmann( Founder of MLOps Community) said:
“Scaling LLMs in production isn’t just about infrastructure, it’s about reliable operations, safety, and iteration speed. That’s where LLMOps becomes the foundation.”
This highlights that LLMOps stands itself as an important element that drives the efficient, smooth, and robust operation of any LLM solution in a production environment, helping businesses to achieve their set goals.
How Does LLMOp’s Work?
LLMOps are included to provide organized and repeatable workflows for deploying, monitoring, and optimizing LLMs across their lifecycle. It takes its inspiration from MLOp’s principles and customizes it accordingly for handling the challenges that LLMs face. To help have an insight into the whole process, we have provided a step-wise breakdown of the methodology, the work behind LLMOp’s, and the tools which are used in each step:
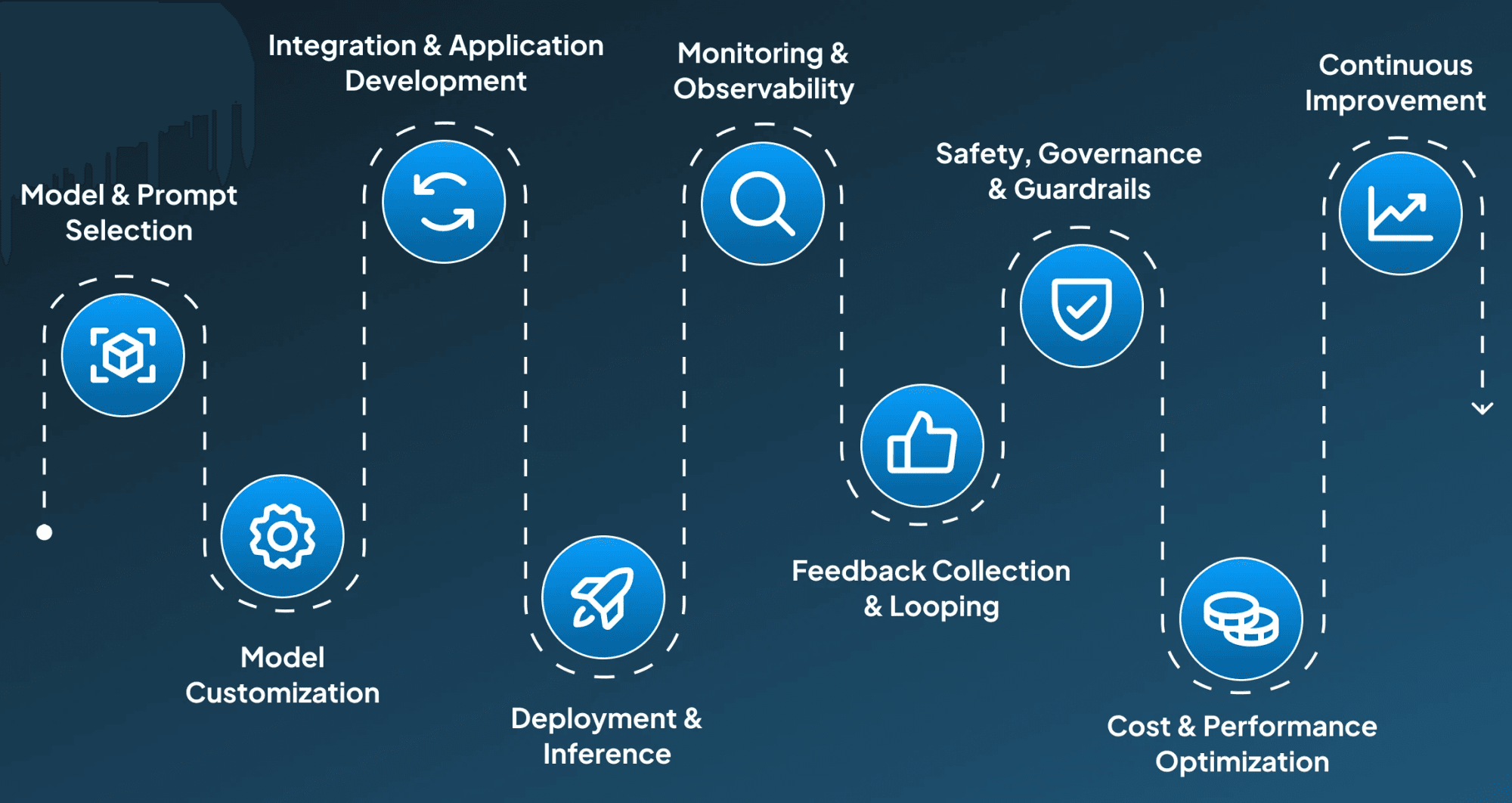
Step 1: Model & Prompt Selection
The process for LLMOps begins with choosing the most suitable pre-trained LLM model and designing customized prompts for the specific use case. These designed prompts are then versioned and tested to ensure consistent and quality outputs throughout the development process.
Tools used:
PromptLayer, Weights & Biases: For prompt versioning and experimentation
Hugging Face Hub, OpenAI, Anthropic: For model sourcing
Step 2: Model Customization (Optional)
After model selection, the next step in the pipeline is fine-tuning or adapting the model by utilizing lightweight or full training approaches to make the model address specific needs. These tailored models are then tracked, stored, and reused using version control systems.
Tools used:
Transformers (Hugging Face), PEFT, DeepSpeed: For training
MLflow, DVC: For tracking experiments and versioning models
Step 3: Integration & Application Development
Once you are done with model customization, the next step to be performed is to integrate models into applications using orchestration tools. This assists engineers in arranging chain prompts, adding memory, and connecting real-time data sources to improve accuracy and user interaction.
Tools used:
LangChain, LlamaIndex: For prompt chaining and RAG
Vector DBs like Pinecone, Weaviate: For contextual memory
Step 4: Deployment & Inference
After preparing the application, it's now time to deploy models efficiently using APIs or infrastructure optimized for inference. For this purpose, routing and batching techniques are implemented to balance speed, quality, and cost at runtime.
Tools used:
vLLM, Triton Inference Server, Ray Serve: For optimized deployment
AWS Bedrock, Azure OpenAI, GCP Vertex AI: For managed serving
Step 5: Monitoring & Observability
The next step in the queue after successful deployment is around continuously monitor the model's performance on metrics like latency, failures, and hallucinations. Under this step, user interactions and responses are logged to identify issues like hallucination and prompt drift. These insight helps the team a lot in debugging problems, identifying anomalies to ensure a smooth and quality user experience.
Tools used:
Weights & Biases, PromptLayer, Arize AI: For monitoring and logging
Sentry, Datadog: For error tracking and infrastructure alerts
Step 6: Feedback Collection & Looping
For improving models' performance over time, the user feedback is collected to evaluate the response quality. Based on the collected feedback, the prompts are refined, parameters are adjusted, or a retraining cycle is triggered to ensure that the model's performance aligns with user expectations.
Tools used:
Truera, Humanloop, OpenAI’s Feedback API: For structured feedback
RLHF pipelines: For reinforcement-based optimization
Step 7: Safety, Governance & Guardrails
Then, in the final steps, it is important to integrate moderation tools to filter unsafe content. These content moderation tools are applied to reduce the occurrence of toxic, biased, or harmful outputs. This compliance with standards and policies is very critical for healthcare, legal, and finance applications.
Tools used:
Azure Content Moderation, OpenAI Moderation, Guardrails AI: For safety filters
WhyLabs, Credo AI: For fairness, explainability, and compliance tracking
Step 8: Cost & Performance Optimization
Running LLMs at scale can be very expensive; therefore, it's essential to optimize compute usage using caching, quantization, and model routing. With LLMOps, we can track performance and resource consumption to find bottlenecks and reduce unnecessary expenditure while delivering high-quality outputs.
Tools used:
Redis, Modal, Replicate: for inference routing and caching
ONNX, TensorRT, bitsandbytes: for model optimization and quantization
Step 9: Continuous Improvement
The last step to follow at the end of the LLMOps cycle is ensuring continuous improvements. For this, Run A/B tests, analyze usage, and improve prompts, models, or infrastructure. Scale systems as needed without disrupting operations.
Tools used:
MLflow, Optuna, Weights & Biases: For experiment tracking
Kubernetes, Terraform: For scalable infrastructure orchestration
Benefits of LLMOp’s
We are witnessing organizations increasingly taking efforts to deploy large language models (LLMs) in real-world applications. Here, adoption of LLMOps is important to ensure operationalization of LLMs, which enables scalable, reliable, cost-effective, and safe systems. Just as MLOps transformed traditional machine learning pipelines, LLMOps enables businesses to run LLMs in production with confidence and control.
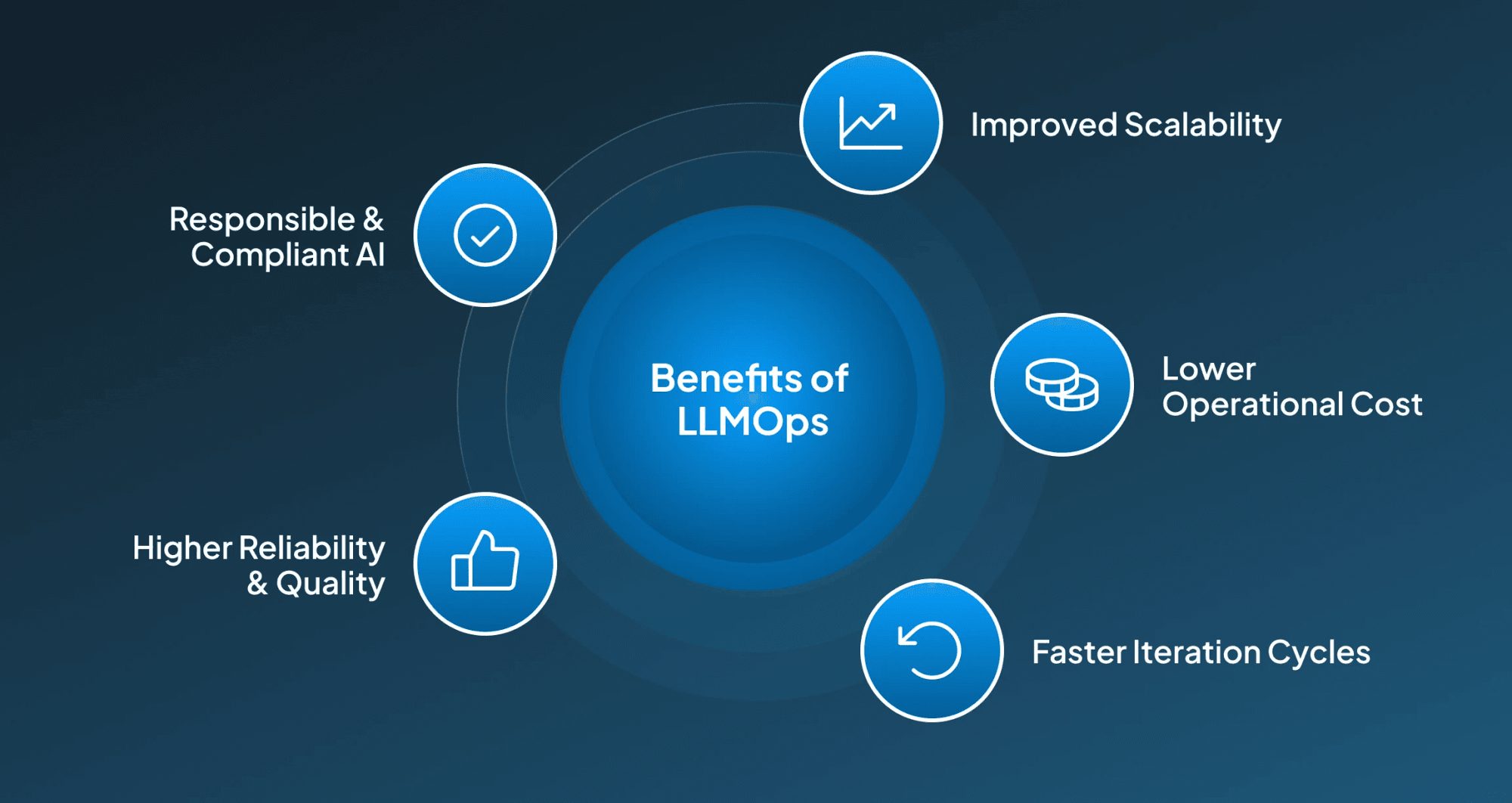
1. Improved Scalability
“Studies have highlighted that LLMOps-driven frameworks for automated deployment and resource management have shown intelligent operations. These frameworks contributed to achieving a 40% boost in resource utilization, a 35% reduction in deployment latency, and a 30% decrease in operational costs compared to the conventional MLOps approaches.” (Mahesh et al., 2025)
2. Lower Operational Cost
By utilizing the LLMOps framework, we can have efficient resource allocation, caching, quantization, and smart model routing to help minimize compute usage, reducing cloud bills and infrastructure strain.
3. Faster Iteration Cycles
“Recent research has shown that a structured feedback approach enabled through LLMOps h improves prompt effectiveness and reliability, directly supporting faster, more systematic iterations in LLM workflows. As the LLMOps frameworks treat output deviation as an error signal to refine prompts over successive iterations, which helps in providing faster iteration cycles.” (Rupesh et al., 2025)
4. Higher Reliability & Quality
LLMops frameworks deliver real-time monitoring, observability tools, and safety checks that enable consistent performance and guard against hallucinations, latency issues, and API failures.
5. Responsible & Compliant AI
LLMOps enables governance with audit trails, moderation tools, and policy frameworks, critical for aligning AI behavior with ethical, legal, and brand standards. This makes sure that the responses remain in line with user expectations.
Limitations of LLMOp’s
Although LLMOps offers critical infrastructure that smoothly manages and scales large language model deployments, it is still an emerging field. As such, organizations may face limitations in tooling, expertise, and integration, especially as models become more complex and use cases more demanding.

1. Tooling is Still Evolving
Contrary to traditional MLOps platforms, these LLMOps lack standardization across multiple tools and frameworks, which makes it harder to build consistent end-to-end workflows.
2. High Initial Complexity
“Research has emphasized that setting up customized LLMOps infrastructure via ontologies, knowledge maps, and prompt engineering significantly improves operational efficiency and scalability. But it requires rigorous testing and validation, and domain-specific expertise to integrate it effectively.” (Panos et al., 2024)
3. Limited Interoperability
“A recent study has shed light that the absence of a standardized reference architecture for LLM-integrated systems can make modularity and interoperability more complex, which makes the integration and evolution of AI systems more complex.” (Alessio et al., 2025)
4. Cost Management Challenges
Despite optimization strategies, operating multiple large models across pipelines remains expensive and requires careful monitoring to avoid resource waste and budget overruns.
5. Ethical and Governance Gaps
The existing tools for LLMOps might not completely support ethical compliance with standards and policies, which may pose a potential risk of having biased responses.
Final Words on LLMOps
In the future, we can predict more demand and dependence of various businesses on LLM-driven tools to unlock more efficiency and growth. Here adoption of LLMOps as base practices is a non-negligible aspect if they want to ensure structured, consistent, and controlled LLM solution performance in a real environment.
With LLMops, they can streamline prompt management, automate model evaluation, and ensure compliance and observability. Therefore, LLMOps empowers teams to scale AI solutions confidently and responsibly. Without it, scalability becomes unsustainable, and performance suffers.
So, now it is the right time for enterprises to invest in robust LLMOps strategies, upskill their teams, and adopt the right tools to ensure their AI systems remain competitive, reliable, and aligned with both business goals and ethical standards. Feeling stuck with unpredictable LLM results or rising deployment costs? Let’s Discuss! Book a quick session with our expert engineers at Centrox AI and see how LLMOps can bring clarity, control, and scale to your AI workflows.

Muhammad Haris Bin Naeem
Muhammad Harris Bin Naeem, CEO and Co-Founder of Centrox AI, is a visionary in AI and ML. With over 30+ scalable solutions he combines technical expertise and user-centric design to deliver impactful, innovative AI-driven advancements.
Do you have an AI idea? Let's Discover the Possibilities Together. From Idea to Innovation; Bring Your AI solution to Life with Us!
Your AI Dream, Our Mission
Partner with Us to Bridge the Gap Between Innovation and Reality.