DALL·E 3 vs Gemini 2.5 Flash Image: Decoding the Next Frontier of AI Image Generation
Compare DALL·E 3 vs Gemini 2.5 Flash Image to discover which AI model best powers your business visuals by decoding how each works.
9/22/2025
DALL·E 3 vs Gemini 2.5 Flash Image
artificial intelligence
11 min read

Where AI image generation once used to sounded like a futuristic idea, today the discussion has transitioned into which model can create high-quality quality accurate images with low latency and resource consumption. Amidst all this DALL·E 3 vs Gemini 2.5 Flash image are two models which have attracted significant user attention.
Both the models DALL-E and Gemini 2.5 Flash Image have taken image generation one step ahead in their own individual ways. This has somehow chosen by selecting anyone model out of these two a bit confusing. While the choice is mostly made on aspects like inference speed, efficiency, cost per image, and prompt-to-image alignment, that's definitely not all to it.
In our blog, we will be answering your query about which model truly surpasses state-of-the-art benchmarks, what architecture drives its performance, and how strong its market utility is. So that you are well aware of your direction, needs, and expectations from these AI image generation models.
AI Image Generation
AI image generation is basically all about using generative AI models like diffusion, GAN, latent diffusion models, transformer-based models, and multimodal foundation architectures. These gen AI models are trained on a large dataset, so that they can learn and understand the underlying pattern for creating images that align best with the provided prompt.
DALL-E 3 Powered AI Image Generation
DALL-E 3 is an image generation model introduced by OpenAI in October 2023. This model is driven by advanced diffusion models and integrated with GPT for image generation. This model ensures excellent prompt accuracy, context-rich visuals, and inpainting capabilities, allowing context-accurate images for creators, marketers, and designers with precision.
How DALL-E Generates Images?
DALL-E 3 has a specialized architecture that powers image generation. This architecture helps the model generate contextually accurate images that align well with the given input prompt. Below, we have provided a step-wise breakdown of this DALL-E 3 architecture, which will help you understand the effort that goes into these image generation models:
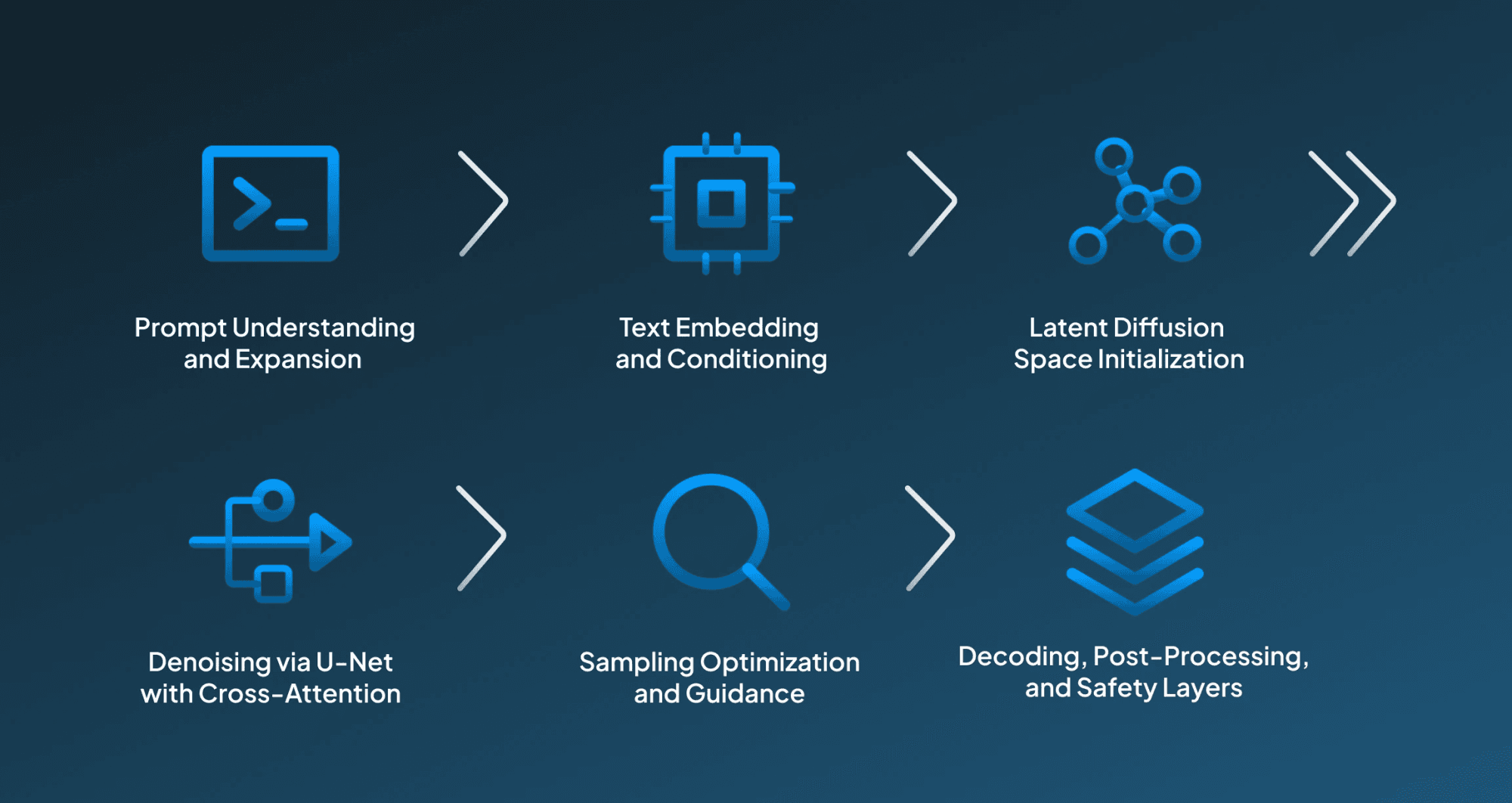
Step 1: Prompt Understanding and Expansion
DALL·E 3 utilizes GPT integration to understand, interpret, and expand the provided input prompts into detailed descriptions. This helps in ensuring that the context, relationships, and visual cues align accurately, with reduced ambiguity. The expanded prompt becomes a rich textual input, making the foundation for precise and contextually aligned image generation.
Step 2: Text Embedding and Conditioning
Then the refined prompt is further encoded into dense embeddings through a transformer-based text encoder. Through these embeddings, it captures the underlying semantic meaning and acts as conditioning inputs for the diffusion model. In this way, it helps the model’s attention layers, ensuring that the generated visuals align well with the described objects, emotions, and spatial arrangements.
Step 3: Latent Diffusion Space Initialization
Then, instead of handling each pixel directly, DALL-E 3 has a latent diffusion model. In its mechanism, it compresses the visual data through a Variational Autoencoder into a latent space, in which the generation initiates when the random noise starts transforming into structured images with precise features through denoising.
Step 4: Denoising via U-Net with Cross-Attention
Then, under its step for denoising, it uses a U-Net architecture enhanced with cross-attention layers that connect image and text features. Under each iteration, the model tends to refine latent noise by aligning textures, colors, and structures to prompt semantics and eventually shaping a coherent and visually appealing image representation.
Step 5: Sampling Optimization and Guidance
Under its final few steps, DALL·E 3 uses classifier-free guidance for controlling prompt adherence and creativity balance. Using advanced sampling techniques, such as flow matching, speeds up the diffusion process while ensuring realism. With this step, it ensures that the generated images are sharp, high-fidelity, and should be reflecting both the intended concept and aesthetic nuance.
Step 6: Decoding, Post-Processing, and Safety Layers
Once the denoising step is done, then in the final step, the latent image is decoded back into pixels using the VAE decoder. This system applies upscaling and artifact correction, which is followed by safety filters and content moderation. Finally, the provenance metadata ensures ethical use, delivering a final, high-quality, policy-compliant image ready for deployment.
Specialized Use Cases of DALL-E 3
With its specialized architecture, this DALL-E 3 can help in creating powerful visuals for various fields and markets. To help you get a better overview, we have mentioned a few use cases where the implementation of DALL-E 3 can help in making the image generation needs faster, smarter, and more detail-oriented.
1. Text-to-Image Accuracy for Marketing & Branding
DALL·E 3 has the potential for generating highly prompt-accurate marketing visuals. With its deep GPT integration, it allows the interpretation of nuanced prompts with precision. Contrary to Midjourney, which leans on artistic flair, this DALL·E 3 delivers brand-consistent and commercially usable image generation.
2. Educational & Informational Illustration
DALL-E has a great ability to make conceptual visuals for educational and conceptual purposes. This is due to its exceptional ability to perform strong contextual grounding. It can accurately generate technical or instructional images like “the structure of a neuron labeled” or “Earth’s atmospheric layers.” While its competitors often struggle with factual accuracy, DALL·E 3 maintains semantic and visual coherence.
3. Storyboarding & Narrative Visualization
This DALL·E 3 model by OpenAI has great capabilities for performing storyboarding, comic creation, and scene visualization. With its advanced ability, it can build its understanding around narrative and elements, while ensuring consistent characters, lighting, and perspective across each scene. Through this ability, it creates the best visuals that align well with the requirements of writers, filmmakers, and animators developing visual scripts.
4. Product Mockups & E-commerce Imagery
In e-commerce and product visualization, DALL-E 3 can make a significant contribution. This model can create realistic rendering and background control. It follows the prompts precisely, which makes it the perfect model choice for carrying out tasks like catalog generation and visual merchandising, where competitors often require manual refinements.
Gemini 2.5 Flash Image Powered AI Image Generation
The Gemini 2.5 Flash Image, also known as Nano Banana, is an image generation model that was released for the general public on October 2, 2025. Since then, the model has shown exceptional ability not only for image generation but also for image editing. This model excels in performing precise conversational editing by just using simple text prompts and generates high-quality visual outputs.
How does Gemini 2.5 Flash Image generate images?
Post the introduction of the Gemini 2.5 Flash image, it has attracted enough user attention, making them inquisitive about the algorithms and architectures that are driving this. This Gemini 2.5 Flash image follows a set of steps to generate the contextually accurate visual that aligns with users' needs. Although the stepwise breakdown isn't widely available, to provide you with a general insight, we have mentioned the general stepwise breakdown of the Gemini 2.5 Flash Image architecture:
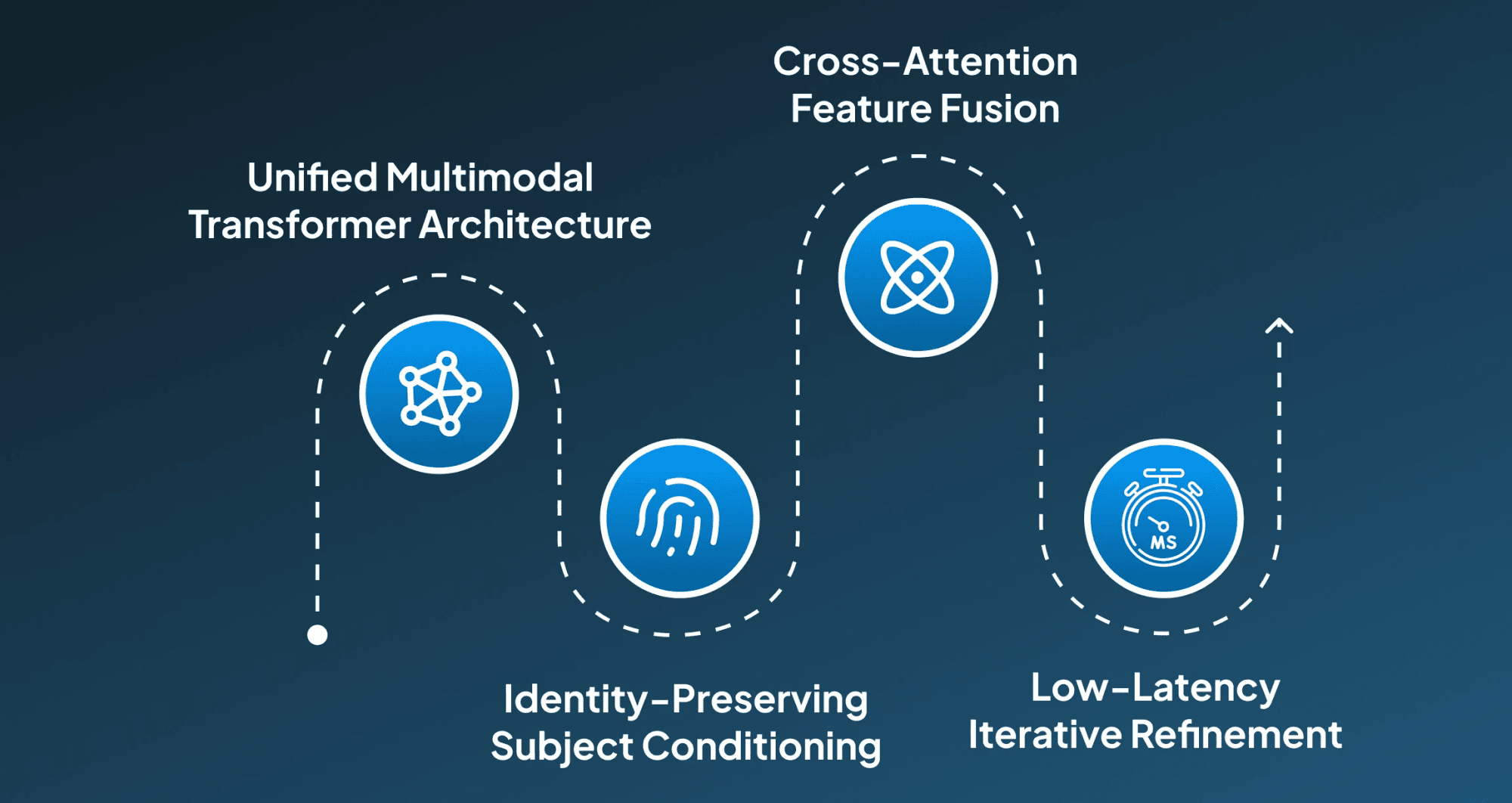
Step 1: Unified Multimodal Transformer Architecture
Under the first step, the single neural network starts natively processing, fusing the visual and language tokens similarly. For doing this, it uses a cross-modal attention within the transformer to deeply integrate information. This allows the modal to reason holistically and apply nuanced edits based on better semantic understanding.
Step 2: Identity-Preserving Subject Conditioning
Additionally, the Gemini 2.5 flash image model employs specialized identity embeddings, which are driven by the subject, which could be character, face, or product features. Then these embeddings function as conditioning vectors, which are injected into the image generation diffusion process across iterative steps to ensure that the specific visual elements remain consistent regardless of scene or pose changes.
Step 3: Cross-Attention Feature Fusion
This mechanism further includes bringing the features together from multiple input images into a unified latent space using cross-attention layers. Through this process, it becomes able to align and merge the diverse elements like a product and a new background, while ensuring the physical laws for creating a contextually coherent, realistic image.
Step 4: Low-Latency Iterative Refinement (LIR)
This Gemini 2.5 Flash Image exhibits flash performance through an efficient, possibly distilled or Sparse Mixture-of-Experts (MoE) model. This step ensures a rapid Time-to-First-Token (TTFT) for image generation. By implementing this, it allows low latency, smooth, real-time conversational editing loop, allowing for fluid, continuous, and interactive refinement of the visual output.
Specialized Use Cases of Gemini 2.5 Flash Image
Gemini 2.5 Flash Image is indeed a significant step in the space of AI image generation, with precision-driven, iterative editing and identity consistency. The integrated architecture of this model allows natural language transformations, seamless compositing, and real-time product styling, ultimately empowering creators to produce quality images for all kinds of contexts without needing to regenerate the entire image.
1. Conversational, Multi-Step Editing (Prompt-Based Transformation)
This Gemini 2.5 flash image is specially optimized for performing iterative conversational editing. This indicates that users can provide this model an image and further ask it to edit according to user instructions using natural language commands. This model generates these transformations in sequence without needing the user to re-mask or regenerate the entire image, and thus ensures a powerful and fluid design workflow.
2. Consistent Character and Subject Identity Preservation
With its powerful ability to identify a subject, this Gemini 2.5 flash image maintains the main subject's identity across multiple edits or scene changes. It means that it captures the particular subject's pose, dressing, and postures to maintain consistency in the generated image. This can make it a very invaluable model, especially for filmmaking or creative branding, where brand consistency in terms of visuals helps in creating, consistent, coherent, and appealing visual storyline.
3. Multi-Image Fusion and Complex Compositing
Another worth mentioning use case of Gemini 2.5 Flash image is around blending multiple inputs into one cohesive and relevant output. For such a use case, users can upload a product photo, a texture image, which could be a marble or anything like that, and a scene photo of a high-end kitchen, then provide it with a prompt to combine them. As a result, it generates a rapid, sophisticated scene, placing a product seamlessly into a lifestyle image or applying a specific style/texture from a reference image.
4. Real-Time Product Styling and Mockup Creation
Gemini 2.5 flash image makes product styling and mockup creation faster and easier. Through its consistency and speedy editing, it stands as a model that produces a wide variety of images just from a single input image. This makes it a very powerful model, especially for e-commerce platforms where the retailer might need the image of a single product from various angles, so instead of capturing it separately every time, this model takes a single image and asks it to generate multiple variations based on specific slighting, angle, and background instructions.
DALL·E 3 vs Gemini 2.5 Flash Image: Performance Evaluation
But the real question is which model is actually leading the way in AI Image generation in terms of performance for specific users' needs and use cases. Although both these models have their own specific abilities and challenges, both have uplifted AI image generation equality generally. While Gemini excels in rapid, cost-efficient generation, DALL·E 3 delivers superior artistic quality, contextual understanding, and precision in text-to-image alignment. The table below compares DALL-E 3 vs Gemini 2.5 Flash Image to help get a better overview of their performance:
Generation Speed | ~3.2 s | ~6 s |
|---|---|---|
Prompt Accuracy | 89–92% | 93–95% |
Image Quality | FID ≈ 8.2 / Rating 8.5–8.7 | Slightly better in artistic tasks |
Cost per Image | ~$0.0025–0.04 | ~$0.04 |
Editing & Fusion | Excellent for multi-image and consistent edits | Strong in literal edits and inpainting |
Best For | Speed, scalability, product visuals | Artistic, detailed, creative visuals |
Which Tool is Better for Powering AI Image Generation?
Both these AI image generation models have introduced a significant leap in the space of image generation. But both of them hold their unique strengths to address different priorities, to help in generating contextually coherent, realistic images for a specific use case input instruction.
Where DALL·E 3 excels in contextual precision, visual richness, and creative storytelling, making it ideal for artistic, marketing, and design-driven use cases. In contrast, Gemini 2.5 Flash Image emerges as a good option for its speed, scalability, and cost-efficiency, perfectly suited for large-scale production and rapid iteration. These models represent their own unique approach to creative fidelity and operational dominance. Industries can make a real profit or procedural advantage by selecting the model that closely aligns with their specific objectives, ensuring that each model not only provides a performance-efficient image but it should also reflects the purpose behind it.
Do you feel overwhelmed by the flood of AI image generation tools? Wondering which model truly fits your creative or business goals? Let’s break through the noise and find the one by discussing it with our experts at Centrox AI, so that you can actually find a model that delivers the best results for your specific use case.

Muhammad Haris Bin Naeem
Muhammad Harris Bin Naeem, CEO and Co-Founder of Centrox AI, is a visionary in AI and ML. With over 30+ scalable solutions he combines technical expertise and user-centric design to deliver impactful, innovative AI-driven advancements.
Do you have an AI idea? Let's Discover the Possibilities Together. From Idea to Innovation; Bring Your AI solution to Life with Us!
Your AI Dream, Our Mission
Partner with Us to Bridge the Gap Between Innovation and Reality.