
Enterprise RAG Development Services for Accurate, Domain-Aware AI Systems
Enterprise AI often suffers from low accuracy, poor domain understanding, and a lack of traceability. Centrox AI's custom RAG development service builds scalable, domain-aware knowledge systems that deliver precise, actionable insights for your business.
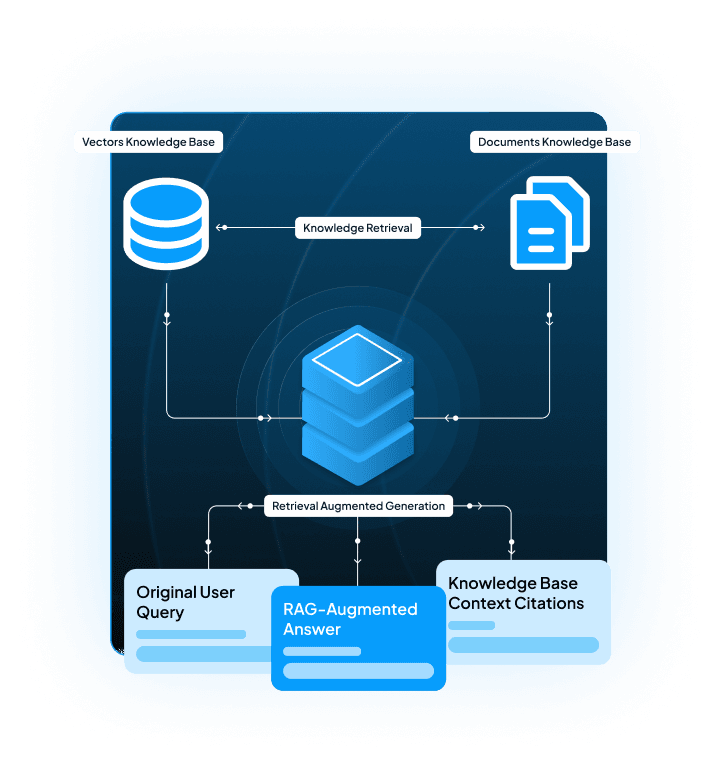








What is Enterprise RAG Development?
Enterprise RAG development is a custom service delivering accurate, traceable AI.

How RAG Works in Enterprise AI

Retrieve
Pulls relevant enterprise data using vector databases and hybrid search.

Augment
Enriches context to generate accurate responses with embeddings and chunking for LLM integration.

Generate
Produces accurate, traceable, domain-specific responses while reducing hallucinations in the generated response.

Ground
Links answers to internal data for secure AI deployment and enterprise automation.
RAG vs Fine-Tuning vs AI Agents
| Feature | RAG | Fine-Tuning | AI Agents |
|---|---|---|---|
| Data Usage | External + real-time data | Static trained data | Dynamic + tool-based |
| Accuracy | High (grounded responses) | Medium (depends on training) | High (task-driven) |
| Hallucination Reduction | Strong | Limited | Moderate |
| Real-Time Updates | Yes | No | Yes |
| Cost Efficiency | High | Expensive retraining | Variable |
| Use Case | Knowledge retrieval | Specialized tasks | Workflow automation |
Enterprise Problems Solved by RAG Systems
Enterprise RAG solutions solve data, search, AI, and workflow challenges efficiently.

Knowledge Management Challenges
Fragmented data across SharePoint, Slack, and Drive.

Inefficient Enterprise Search
Keyword-based search fails to find context-aware insights.

AI Hallucinations & Risk
Unreliable outputs increase business and compliance risks.

Manual Workflows & Repetitive Tasks
Time-consuming processes that slow enterprise productivity.
Enterprise Use Cases of RAG
From internal knowledge assistants to customer-facing copilots, we deploy RAG across every function of the modern enterprise.
AI for Internal Knowledge Management
Centralizes and accesses enterprise knowledge efficiently for generating context-aware responses from the RAG solution.
Customer Support Automation
Deliver instant, accurate responses with RAG-powered assistants.
Legal Document Analysis
Extract insights and reduce manual review time with a RAG-based solution.
Financial Data Insights
Centralizes and accesses enterprise knowledge efficiently for generating context-aware responses from the RAG solution.
Healthcare Knowledge Systems
Our RAG developed solution improves decision-making with secure, data-driven AI systems.
Every enterprise has unique retrieval challenges. We tailor RAG architecture, data connectors, and retrieval strategies to your specific use case and data landscape.
Our Enterprise RAG Development Services
Custom RAG System Development
Tailored custom RAG development to build scalable, context-aware enterprise AI systems.
Enterprise Knowledge Assistant
AI knowledge assistants that deliver instant, accurate insights from your enterprise knowledge base.
AI-Powered Search & Q&A Systems
Advanced enterprise search automation with precise, context-aware responses.
Document Intelligence & Automation
Automate document processing using AI for faster data extraction and decision-making.

AI Copilots for Internal Operations
Boost productivity with AI copilots for enterprises across workflows and teams.

Multi-Source Data Integration
Seamlessly connect CRMs, APIs, databases, and documents into a unified AI system.
Enterprise RAG Architecture We Build
Data Ingestion Layer
Ingest data from PDFs, CRMs, APIs, and enterprise systems through robust document ingestion pipelines.
Embedding & Vector Database Layer
Use embeddings & chunking with vector databases like Pinecone, FAISS, and Weaviate.
Retrieval Layer
Enable hybrid search (dense + sparse) with intelligent reranking for accurate information retrieval.
LLM Layer
Integrate GPT and open-source models for scalable, context-aware AI generation.
Security & Governance Layer
Ensure secure AI deployment with RBAC, encryption, and enterprise-grade compliance.

Advanced RAG Capabilities We Implement
Agentic RAG Systems
Build autonomous, task-driven AI systems for extremely critical enterprise daily tasks.
Hybrid Search
Combine semantic and keyword search for enhanced retrieval accuracy.
Multi-Hop Reasoning
Enable AI to connect multiple data points for deeper insights in generated responses.
Real-Time Data Sync
Keep AI responses up-to-date with live enterprise data.
Source-Cited Responses
Provide traceable outputs linked to internal data sources.
Technology Stack for Enterprise RAG Development
We use enterprise-grade AI infrastructure tools including:
OpenAI
Claude
Llama
Mistral
LLMs & Foundation Models
LangChain
CrewAI
spaCy
HF
RAG Frameworks
Elastic

BigQuery

Databricks
Data & Vector Stores
AWS
Azure

GCP
Cloud & Infrastructure

Prometheus
Grafana
Monitoring & Ops
RAG Evaluation and Optimization
We evaluate enterprise RAG performance using measurable benchmarks:

Retrieval accuracy improvement
Measures how effectively relevant enterprise data is retrieved for queries.

Hallucination rate reduction
Tracks reduction in AI-generated errors and unsupported responses.

Semantic relevance scoring
Evaluates how contextually accurate and meaningful responses are.

Context precision & recall
Measures how well the retriever selects relevant chunks without noise.

Response grounding confidence
Ensures outputs are reliably linked to enterprise data sources.

Latency optimization metrics
Monitors response speed for real-time enterprise performance.
Enterprise RAG Across Every Industry
RAG-powered AI is transforming knowledge management in every sector. Centrox deploys tailored RAG solutions across industries with deep domain requirements.

Intelligent legal research and document analysis
Deployment Options for Enterprise RAG !!!

On-Premise
Full control with secure, internal AI systems

Private Cloud
Scalable and secure cloud-based deployment

Hybrid
Combine on-premise and cloud for flexibility and performance
Our RAG Development Process
- 1
Discovery & Use Case Mapping
Identify business needs and define RAG use cases.
- 2
Data Preparation & Integration
Clean, structure, and connect enterprise data sources.
- 3
Architecture Design
Design scalable RAG pipelines with optimal components.
- 4
Development & Testing
Build, test, and optimize for performance and accuracy.
- 5
Deployment & Monitoring
Deploy with continuous monitoring, updates, and optimization.

Why Choose Centrox for Enterprise RAG Development
Enterprise-Grade Security & Compliance
We ensure secure RAG deployment with strict governance standards.
Custom Architecture Design
We ensure secure RAG deployment with strict governance standards.
Scalable AI Infrastructure
Our RAG development services ensure that your solution handles large-scale enterprise workloads.
Proven Enterprise Use Cases
Experience across industries and real-world deployments.
LLMOps & Continuous Optimization
Ongoing monitoring, tuning, and performance improvement.
We're Often Asked
Retrieval-Augmented Generation (RAG) is an advanced AI architecture that connects Large Language Models (LLMs) to your proprietary enterprise data. Unlike generic bots, enterprise RAG retrieves relevant, secure, and up-to-date information from your internal databases, documents, and APIs before generating an answer, ensuring factually accurate and deeply contextual responses.
RAG typically utilizes real-time data retrieval from enterprise systems to produce responses, whereas fine-tuning trains models on static datasets. This allows RAG to be more flexible, up-to-date, and cost-efficient, as it eradicates the need for frequent retraining while still delivering accurate and context-aware insights.
Yes, when built correctly. Enterprise RAG pipelines are designed with strict security protocols. Responses are generated entirely within your secure cloud boundary, respecting Role-Based Access Control (RBAC). The LLM never 'learns' or leaks your data, and only employees authorized to see a document can retrieve data from it.
RAG eliminates AI hallucinations by grounding responses in your actual data. It provides up-to-date information without expensive retraining, offers full source citation for trust and auditability, and dramatically reduces the time employees spend searching for knowledge across fragmented internal systems.
The cost varies depending on the scale and complexity of the deployment, including factors like data sources, vector database configuration, LLM token usage, and necessary security compliances. Centrox builds highly optimized, cost-efficient RAG architectures tailored to avoid unnecessary cloud or token overhead.
Virtually any data-rich industry can benefit from RAG. We frequently deploy RAG solutions for Law Firms (contract analysis), Healthcare (medical record search), Fintech (report abstraction), Retail (inventory insights), and Manufacturing (equipment maintenance manuals).
Enterprises should opt for RAG when they need an AI assistant that can answer highly specific domain or internal questions, when their data changes frequently, or when accuracy and source citation are mission-critical. It is the premier choice over fine-tuning for dynamic knowledge retrieval.
Depending on your data readiness and security requirements, a robust pilot or MVP can be deployed in 4 to 8 weeks. A full-scale integration connected to complex multi-source enterprise data architectures generally takes a few months to fully optimize, test, and securely launch.
Maintenance costs primarily encompass LLM inference (token usage), vector database hosting, and routine LLMOps monitoring. Since RAG does not require constant retraining to learn new data, it is significantly cheaper to maintain over time compared to traditional fine-tuned models.
Contact Us
What happens next?
- 1
Once we get your request, we’ll reach out soon to understand your project better and secure everything with an NDA.
- 2
Our team digs into your needs and whips up a project plan, including timelines, team size, and budget.
- 3
We hop on a call to go over the plan and make sure we’re all on the same page.
- 4
With the contract signed, we jump right into making your project happen.
25+
Solutions Provided
50+
Experts
100,000
People Benefitted