
LLMOps Advisory Services for Scalable and Reliable Enterprise AI Systems
With our LLMOps advisory services, we ensure full-cycle LLMOps handling for enterprises. From management, deployment, and scaling LLMs, we enable reliable, controlled production. Our LLMOps solution provides consistent, efficient performance throughout monitoring, evaluation, governance, and optimization. Through this, we build AI systems that exhibit reduced hallucinations with controlled costs for enterprise infrastructure.
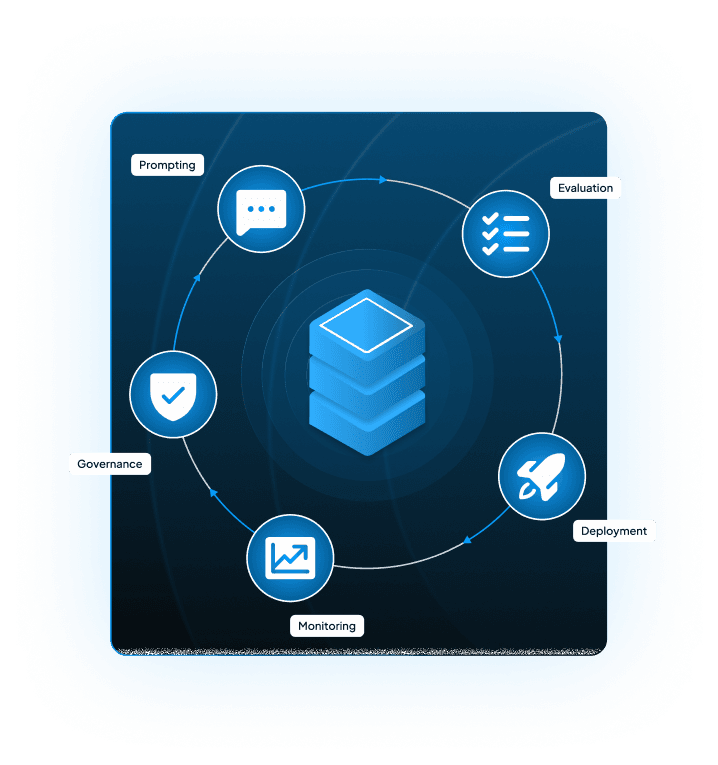









How LLMOps Extends Traditional MLOps
For enterprises, MLOps generally manages the ML pipeline from data to deployment, whereas LLMOps handles LLM challenges like prompt management, hallucination, and cost-heavy deployments.
| Feature | MLOps | LLMOps |
|---|---|---|
| Model Type | Conventional ML models (e.g., regression, classification, decision trees,) Neural networks, and CNN | Large Language Models (e.g., GPT, LLaMA, Claude) |
| Development Focus | Data preprocessing, training, validation | Prompt engineering, fine-tuning, retrieval-augmented generation (RAG) |
| Deployment | Deploying custom-trained models | Using pre-trained models via APIs or hosting huge models efficiently |
| Cost & Resources | Typically less resource-intensive | High compute and memory requirements (GPU-heavy) |
| Monitoring Needs | Model accuracy, drift, and retraining triggers | Output quality, hallucinations, prompt drift, latency |
| Optimization | Hyperparameter tuning, data pipeline tuning | Prompt tuning, quantization, and adapter models (e.g., LoRA) |
| Human Feedback | Often limited to offline labeling | Continuous feedback (e.g., thumbs up/down, RLHF) |
| Tooling | ML pipelines (e.g., MLflow, Kubeflow) | LLM-specific tools (e.g., LangChain, Weights & Biases with LLMOps plugins) |
Role of LLMOps in Enterprise AI Systems
LLMOps holds a significant importance in LLM lifecycle management and AI infrastructure management since they offer very significant value to the enterprise AI system.
Stability
Our LLMOps implementation services extend stable LLM deployment pipelines.

Scalability
LLMOps implementations ensure reduced hallucination and scalable LLM systems for the enterprise.

Governance
LLMOps enables LLM engineering, specifically addressing AI governance issues.
Business Problems Solved by LLMOps
Your LLM solution isn't failing because of the idea; it's failing because it isn't equipped with the necessary LLMOps practices.

Unstable AI Outputs in Production
LLM solutions with hallucinated responses in production impact enterprises' workflow.

Lack of Monitoring and Observability
The LLM solution doesn't meet enterprises' expectations because of a lack of LLM monitoring systems.

High AI Infrastructure Costs
LLM infrastructure for enterprises has high token usage because of inefficient model routing.
Difficulty Scaling AI Systems
Enterprise AI infrastructure struggles to scale because of unoptimized latency and token usage.
Our LLMOps Consulting Services
Our LLMOps advisory services provide reliable LLM deployment pipelines, ensuring that your LLM systems don't fail in production.

LLMOps Strategy and Architecture Consulting
We provide system design and operational frameworks with model version control.

LLM Deployment and Infrastructure Setup
Centrox extends cloud, on-prem, and hybrid deployment with AI evaluation frameworks.

LLM Monitoring and Observability Systems
Ensure round-the-clock tracking for performance, latency, and outputs with LLM monitoring systems.

LLM Evaluation and Testing Frameworks
AI evaluation that gives accuracy, hallucination detection, and benchmarking for the generated outputs.

Prompt and Model Lifecycle Management
Enterprise AI infrastructure that holds versioning, testing, and optimization.

AI Governance and Security Implementation
LLM lifecycle management services that uphold compliance and access control.
LLM Cost Optimization Systems
Deliver AI systems with optimized token usage tracking, caching, and routing
Enterprise LLMOps Architecture We Build
LLMOps Architecture that guarantees enhanced operations for enterprises' everyday tasks.
Data and Input Layer
Ensures AI infrastructure management with data ingestion via APIs
Retrieval and Knowledge Layer
Holds RAG systems with RAG monitoring powered by vector databases
LLM Inference Layer
Adaptive AI model deployment enabled through distributed inference systems
Agent and Application Layer
AI systems are designed to empower agents, copilots, and workflows.
Monitoring and Evaluation Layer
AI model deployments enabling performance monitoring with tracking and evaluation
Governance and Security Layer
AI governance issues resolved with enterprise LLM reliability engineering

AI Capabilities Included in LLMOps
LLMOps Advisory services that ensure expert deployment and performance in production

LLM Monitoring and Observability
LLM lifecycle management, overlooking outputs, latency optimization, and performance

Prompt Engineering and Versioning
Enables prompt versioning to produce context-aware AI outputs

Automated Evaluation Systems
AI monitoring tools that flag model performance degradation and drift

Cost Optimization Mechanisms
Ensures optimized token usage to reduce inference cost across the enterprise solution

Scalable Deployment Pipelines
LLM deployment pipelines that make sure efficient production AI systems
Enterprise Use Cases of LLMOps
LLMOps use cases to optimize the workflow efficiency of enterprises.

AI Knowledge Assistants with RAG
RAG infrastructures enabling scalable AI systems for enterprise knowledge

Customer Support AI Systems
LLM lifecycle systems that ensure minimized hallucinations in support chatbots

Legal AI Systems
AI systems customized to address daily issues in legal document analysis systems

Financial AI Applications
Model drift detection implemented to enhance reporting and risk analysis accuracy

AI Copilots for Operations
AI models specially developed to empower copilots for workflow automation
Technology Stack for Enterprise LLMOps
We use enterprise-grade LLMOps infrastructure and lifecycle management tools, including:
GPT
Llama
Mistral
Claude
LLM Models
LangChain

LlamaIndex

Haystack
Frameworks & Orchestration

Pinecone

Weaviate

FAISS

Milvus
Vector Databases

Weights & Biases

LangSmith

Arize AI

Helicone
LLM Monitoring & Observability

PromptLayer

Humanloop
LangSmith
Prompt Management & Versioning

Ragas

DeepEval

TruLens
Evaluation & Testing Frameworks

vLLM
TensorRT-LLM
Hugging Face TGI
Deployment & Inference Infrastructure
AWS
Azure

GCP
Cloud Platforms

REST APIs
GraphQL
OpenAI API

Anthropic API
API & Integration Layer

Snowflake

BigQuery

Databricks
Data & Storage Systems
Industry Applications of LLMOps
Intelligent LLMOps implementation is improving performance across various essential industries

Secure LLM lifecycle management for compliant legal AI systems
LLMOps vs MLOps
| Feature | MLOps | LLMOps |
|---|---|---|
| Model Type | Traditional ML | Large Language Models |
| Data Type | Structured | Structured + Unstructured |
| Monitoring | Model Performance | Output Quality + Prompts |
| Cost Tracking | Limited | Token-level Cost Tracking |
| Adaptability | Moderate | High |
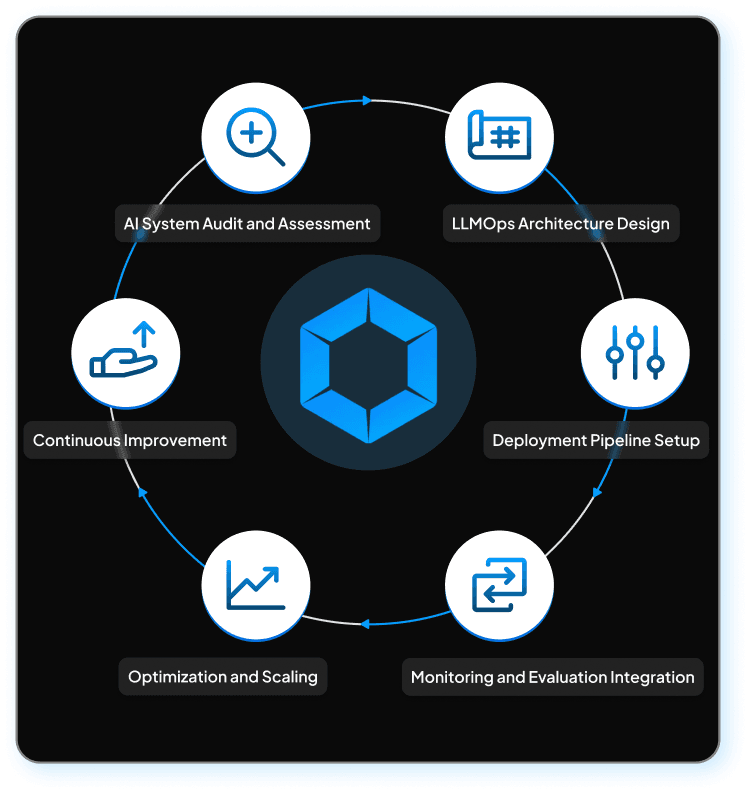
Our LLMOps Implementation Process
Intelligent LLMOps implementation process is specially engineered to meet optimal performance
- 1
AI System Audit and Assessment
Recognizes failures and scaling issues of the enterprise AI system
- 2
LLMOps Architecture Design
Design an enterprise AI infrastructure that ensures optimized performance for the entire workflow
- 3
Deployment Pipeline Setup
Implement efficient LLM deployment pipelines for production AI systems
- 4
Monitoring and Evaluation Integration
Enable reliable integration of AI monitoring models and evaluation frameworks
- 5
Optimization and Scaling
Optimize resource consumption and processing latency for enterprises' daily tasks
- 6
Continuous Improvement
Ensures smooth performance of AI infrastructure through continuous prompt versioning
Enterprise Integrations We Support
Seamlessly integrate your LLMOps stack with enterprise-ready AI infrastructure.

AWS
Support scalable AI workflow automation with cloud-native integrations.

Azure
Automate emails, documents, and collaboration workflows with AI.

Google Cloud
Enable real-time data-driven automation using AI-powered analytics.

APIs
Support scalable AI workflow automation with cloud-native integrations.

Vector Database
Automate emails, documents, and collaboration workflows with AI.
Benefits of LLMOps Consulting Services
LLMOps advisory services that enhance enterprise workflow productivity.
Reliable AI Performance
LLM lifecycle management that guarantees reliable AI performance
Reduced AI Costs
Enterprise LLMOps infrastructure that promises low inference cost
Faster Deployment
AI systems built with faster LLM deployment pipelines
Improved Output Accuracy
LLM systems generating inference with reduced hallucination and promising accuracy
Scalable AI Infrastructure
Generative AI operations that scale with distributed inference systems
Challenges We Solve in LLMOps Implementation
Our LLMOps implementation addresses all the challenges and adapts intelligently for future problems.
Hallucination Control
AI systems that ensure context-aware, stable AI outputs with reduced hallucinations

Cost management
An LLM deployment pipeline that ensures low inference cost for enterprise workflow

Model scaling
Enables production AI systems thats scales according to enterprise needs

Data privacy
Handles data with responsibility to ensure privacy across the LLM infrastructure

System integration
Ensuring reliable and efficient LLM lifecycle management with smarter integrations
Why Choose Centrox for LLMOps Consulting
LLMOps development that generates reliable and stable AI outputs to cater to enterprises' needs.

Enterprise-Grade AI Infrastructure
Smart AI infrastructure developed to address an enterprise's everyday workflow needs.

Deep Expertise in RAG and AI Agents
AI models orchestrated with robust RAG systems and AI agents

Secure and Compliant Systems
AI evaluation frameworks that ensure compliance and security across enterprise systems

Scalable Architecture Design
LLM Architectures are designed to scale for enterprise needs.
End-to-End AI Lifecycle Management
LLM lifecycle management from data preparation to deployment and monitoring.
FAQs
LLMOps refers to managing large language models across their lifecycle, including deployment, monitoring, optimization, and governance. It ensures that production AI systems remain reliable, scalable, and cost-efficient while addressing challenges such as hallucinations, performance degradation, and infrastructure complexity.
LLMOps is basically an extension of MLOps, which specifically addresses the management of Gen AI operations by performing prompt versioning, monitoring output, and implementing token-level cost tracking. Unlike traditional ML implementations, this approach handles unstructured data, probabilistic outputs, and even dynamic workflows for enterprise AI systems.
LLMOps is particularly important for enterprises' AI infrastructure, as it powers the scalability, security, and reliability of such solutions. LLMOps particularly addresses issues like hallucinated outputs, reliability, and high inference costs, to ensure confident deployment and management of production-grade Gen AI applications for enterprise.
Enterprises should definitely consider investing in LLMOps when they are planning to move their solutions from a prototyping environment to a production environment. Enterprise solutions that delay implementing LLMOps early struggle to scale, have high inference cost, unstable output, and lack monitoring, leading to a system prone to fail in production.
We evaluate LLM performance through our expert observability tools that regularly look after the output quality, time it takes, token consumption, and error rates for generated inferences. Our systems are made with proficient AI evaluation frameworks, drift detection, and real-time monitoring systems that help in recognizing hallucinations, performance issues, and optimization opportunities for your AI enterprise solution.
We ensure data security for your sensitive enterprise through our customized LLMOps implementation. Our LLMOps ensures complete data privacy through encryption, access controls, and compliance with all the AI governance frameworks. With our secure APIs, private deployments, and governance policies, we ensure no data leakage, so that your enterprise solution follows all the regulatory and privacy requirements.
Implementation of LLMOps costs vary according to the complexity, scale, and customized needs of your AI systems. The cost of your LLMOps implementation is tailored according to your enterprise infrastructure model usage, integrations, and monitoring systems used for it. These solutions are mindfully architected to adapt to long-term scalability needs.
We use specialized LLMOps tools for planning, monitoring, and deployment, including vector databases, prompt management systems, and evaluation frameworks. Cloud platforms and APIs support scalable infrastructure to ensure that your enterprise solution works efficiently while consuming resources in an optimized way.
LLMOps implementation timelines are directly dependent on the scale, complexity, and integrations required for your specific enterprise use cases. Setting up for basic tasks consumes weeks, while enterprise-scale deployments with monitoring, governance, and optimization layers can take several months for full-scale production readiness with no failures.
Talk to Our AI Expert
Book an exclusive 1:1 call today with our AI expert to discuss and discover what we can do to accelerate your LLMOps implementation.
Contact Us
What happens next?
- 1
Once we get your request, we’ll reach out soon to understand your project better and secure everything with an NDA.
- 2
Our team digs into your needs and whips up a project plan, including timelines, team size, and budget.
- 3
We hop on a call to go over the plan and make sure we’re all on the same page.
- 4
With the contract signed, we jump right into making your project happen.
25+
Solutions Provided
50+
Experts
100,000
People Benefitted